Продолжаем репортаж с обеих площадок главной ML-конференции года. Новости из американского Сан-Диего читайте в канале ML Underhood. А двумя примечательными докладами из Мехико поделится Дмитрий Быков, руководитель группы AI-планирования робота доставки.
Спойлер: речь пойдëт об обучении с подкреплением.
The OaK Architecture: A Vision of SuperIntellegence from Experience
Выступление Rich Sutton о том, каким он видит суперинтеллект.
Первое, на что он обращает внимание, — авторы большинства работ вносят во множество доменов знания, которые помогают решить конкретные задачи. Но одновременно с этим их вклад начинает влиять на результаты работы моделей и делает их неоптимальными.
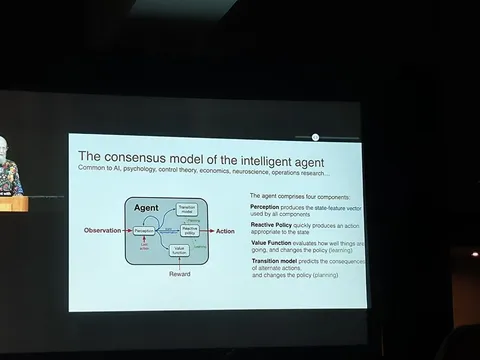
У суперинтеллекта, по его мнению, должно быть понятное представление о награде. Такое, чтобы у него появились все верхнеуровневые признаки, необходимые для формулирования подзадач, решение которых будет приближать награду.
При появлении новых признаков должна разрастаться и transition model (пространство действий которые возможно совершить).
PRINT: Preference-based Reinforcement Learning with Multimodal Feedback and Trajectory Syntesis from Foundation Models
Ребята сделали схему для обучения моделей, которые управляют роботом. В итоге смогли обогнать методы на моделях с одной из модальностей.
Сконструировать нормальный реворд сложно, а ручная разметка — очень дорогая. Чтобы обойти это, авторы попробовали обучаться на предпочтениях, сгенерированных моделями.
Несмотря на то, что текстовые модели любят галлюционировать, а VLM плохо сохраняют временные взаимодействия, их комбинация работает сильно лучше — они компенсируют недостатки друг друга.
В начале обучения авторы обходятся траекториями, сгенерированными LLM: генерируют, перемешивают и просят LLM выбрать лучшую. А дальше объединяют вердикты LLM и VLM.
Ещë один трюк — включение в лосс причинности. Так за счëт модели получается найти лучшие варианты и вознаградить их.
#YaNeurIPS25
Заметил на конференции
404 driver not found