Сегодня разберём очередной техрепорт от Shopee — маркетплейса, популярного в Южной Америке и Азии. Авторы представляют новый фреймворк OnePiece, где адаптируют LLM и к retrieval, и к ранжированию.
Идеи, на которых основан подход, простые, но интересные:
— Structured context engineering: обогатить историю взаимодействия с пользователями.
— Block-wise latent reasoning. Авторы в некотором роде придумали, как прикрутить к рекомендательным системам reasoning от LLM.
— Progressive multi-task training: прогрессивно усложнять обучающие задачи для учёта фидбека.
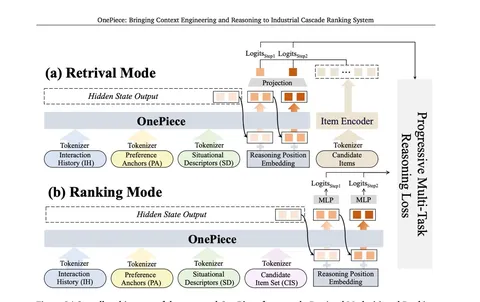
По названию материала можно было бы подумать, что речь пойдёт про одностадийную модель, но нет. Как заведено в современных рекомендательных системах, стадии две: retrieval и ranking.
В основе модели — энкодер с трансформером. Размеры в статье не приводят, но по косвенным признакам, модель не очень большая.
Подробности можно рассмотреть на схеме. Начнём с retrieval. Вход стандартный: история взаимодействий, описание контекста через пользовательские фичи. Из интересного — preference anchors, которые помогают собрать топы товаров по количеству покупок, добавлению в корзину или кликов. Можно сказать, что это аналог RAG (от LLM) для рекомендашек.
Для стадии ранжирования — то же самое, плюс множество кандидатов, как в подходе с target-aware-трансформером.
Представление входов довольно стандартное. Товары описываются набором ID: название, магазин, категория. Запросы представлены мешком слов. Токены получаются с помощью MLP над конкатенацией эмбеддингов.
Если не использовать маскирование, получится полный attention между всеми кандидатами. Чтобы сэкономить compute и избежать артефактов в зависимостях, авторы выбрали промежуточный вариант: делят кандидатов на рандомные группы и подают на вход по одной.
Backbone тоже стандартный и не стоит отдельного внимания. А вот reasoning интересный. Почему? Расскажем в следующем посте!
@RecSysChannel
Разбор подготовил