Сегодня разберём статью от компании Google DeepMind, главный фокус которой в последнее время — LLM в рекомендациях. У рекомендательных моделей есть ряд преимуществ относительно более традиционных рексистем: богатое понимание мира, ризонинг, способность объяснять, почему был порекомендован тот или иной объект, и многое другое. Но это не отменяет слабые места, например, проблему динамики в интересах пользователей и корпусе айтемов. Именно этот аспект авторы разбирают в статье.
Эксперименты проводятся в YouTube Shorts. Авторы выясняют: нужно ли вообще обновлять рекомендательную LLM в таком домене, или со своим знанием мира она и так справится. Отвечают интересным экспериментом: кластеризуют тематики шортсов и по логам пользователей собирают тройки (c1, c2, c_next) кластеров, с которыми кто-то последовательно провзаимодействовал. Делают так отдельно для нескольких месяцев, после чего для всех пар (c1, c2) собирают топ-5 переходов в c_next для каждого месяца i: {c_next_1, …, c_next_5}_i. Далее для пар (c1, c2) считают IoU множеств переходов за соседние месяцы (i vs. i+1) и получают низкое значение 0,17, что подчеркивает высокую изменчивость паттернов пользователей во времени. Отсюда возникает необходимость постоянного обновления рекомендательной LLM.
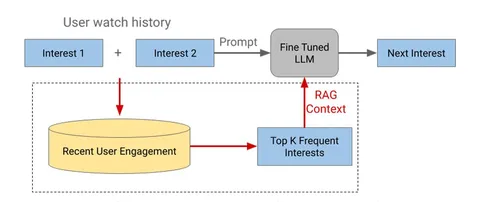
В статье сравниваются два метода: fine-tuning и RAG. Первый обновляет веса модели через дообучение на новом трафике. Второй, грубо говоря, усиливает промпт недостающей информацией о пользователе и домене, при этом никак не влияет на саму модель.
Fine-tuning. Модель дообучается предсказывать следующий кластер, с которым провзаимодействовало большинство пользователей: (c_1, c_2, …, c_n) → c_{n+1}. Описания кластеров поступают в LLM в словесной форме. Из минусов метода — сложность, возможность переобучения и высокие вычислительные затраты. Из-за последнего дообучение происходит лишь ежемесячно.
RAG. Точно так же представляет историю в виде последних взаимодействий с кластерами (обновленные интересы пользователя), но ещё и добавляет в промпт наиболее популярное продолжение для этой последовательности взаимодействий (обновленные реалии домена). Поскольку множество всевозможных историй вида (c_1, c_2, …, c_k) невелико и конечно, инференс производится несколько раз в неделю, а предпосчитанные кандидаты для каждой истории достаются в реальном времени лукапом.
В офлайн-эксперименте проверяют, нужен ли RAG и стоит ли пересчитывать кандидатов раз в несколько дней. Оказывается, что на оба вопроса ответ положительный. В A/B-тесте отчитываются о приростах Satisfied User Outcomes, Satisfaction Rate и об уменьшении Dissatisfaction Rate и Negative Interaction.
@RecSysChannel
Разбор подготовил