Сегодня разбираем статью от исследователей из Renmin University of China и Kuaishou Technology, представленную на RecSys'25. Работа посвящена объединённому моделированию поиска и рекомендаций с использованием генеративного подхода на основе больших языковых моделей.
Современные коммерческие платформы (e-commerce, видео, музыка) предлагают одновременно и поиск, и рекомендации. Совместное моделирование этих задач выглядит перспективно, однако авторы выявили ключевой trade-off: улучшение одной задачи часто приводит к деградации другой.
Причина кроется в различных информационных требованиях:
— Поиск фокусируется на семантической релевантности между запросами и айтемами — традиционные варианты поиска часто основаны на предобученных языковых моделях (BGE, BERT);
— Рекомендации сильно зависят от коллаборативных сигналов между пользователями и айтемами — ID-based-рекомендации дают отличные результаты.
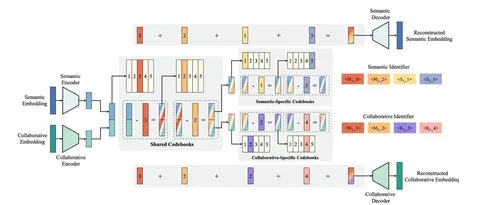
GenSAR — унифицированный генеративный фреймворк для сбалансированного поиска и рекомендаций.
Для каждого айтема берутся два эмбеддинга: семантический (из текста) и коллаборативный (из user-item-взаимодействий). Оба прогоняются через отдельные MLP-энкодеры и приводятся к одной размерности, затем конкатенируются в общий вектор.
Объединённый вектор квантуется через общие кодбуки: на каждом уровне выбирается ближайший код, его индекс записывается в идентификатор, а сам код вычитается из текущего вектора. Накопленная последовательность — это shared prefix, содержащий общую информацию обоих эмбеддингов.
Далее остаточный вектор делится пополам. Одна половина подаётся в семантические кодбуки, другая — в коллаборативные. В итоге:
— Semantic ID (SID) = shared codes + semantic-specific codes;
— Collaborative ID (CID) = shared codes + collaborative-specific codes.
Лосс состоит из суммы:
1) Reconstruction loss: декодеры должны восстановить исходные эмбеддинги по кодам.
2) Loss for residual quantization: считается для трёх наборов кодбуков (shared, semantic, collaborative) и включает codebook loss + commitment loss для каждого.
Выход модели зависит от задачи:
- Рекомендации → CID (коллаборативный сигнал важнее);
- Поиск → SID (семантика важнее);
Модель различает задачи через task-specific-промпты. Обучение — joint training на смешанных батчах с балансировкой лоссов между задачами.
Оффлайн-эксперименты проводились на публичном датасете Amazon и коммерческом датасете Kuaishou. Сравнение с бейзлайнами: SASRec, TIGER (рекомендации), DPR, DSI (поиск), JSR и UniSAR (совместные модели).
На Amazon GenSAR показывает +12,9% по Recall@10 для рекомендаций и +12,8% для поиска относительно лучшего бейзлайна UniSAR. На коммерческом датасете Kuaishou прирост составляет +10,4% и +11,7% соответственно.
Ablation study подтверждает важность обоих компонентов:
— Без CID качество рекомендаций падает на 8,9%;
— Без SID качество поиска падает на 14,7%;
— Dual-ID подход даёт +12,7% к рекомендациям по сравнению с single-ID.
@RecSysChannel
Разбор подготовили