Сегодня посмотрим на совсем свежую статью от NVIDIA о сжатии KV-кэша. KV-кэш — это сохраненные K- и V-стейты трансформера для последующей авторегрессивной генерации токенов в декодере. В первую очередь проблема сжатия возникает на стадии генерации в LLM, однако она актуальна и для ускорения инференса рекомендательных моделей, например, имеющих encoder-decoder-архитектуру.
Размер KV-кэша линейно зависит от числа слоёв трансформера L, от числа аттеншн-голов H, от длины входной последовательности T и от размерности векторов D. Таким образом, он имеет размерность (2, L, H, T, D), где 2 соответствует хранению K- и V-кэшей в одном тензоре. Сжатие по L-размерности достигается чередованием обычных MHA-слоёв и слоёв со Sliding Window Attention (SWA): GPT-OSS-120B, Gemma3, Kimi-Linear, и др. Для сжатия по размерности H применяют Grouped Query Attention (GQA), в котором одни и те же KV-головы используются в нескольких Q-головах: Llama3, GLM 4.5, Qwen3-235B-A22B. Вдоль размерности D сжатия добиваются с использованием хранения латентных представлений KV-векторов значительно меньшей размерности — Multi-head Latent Attention (MLA): DeepSeek V2.
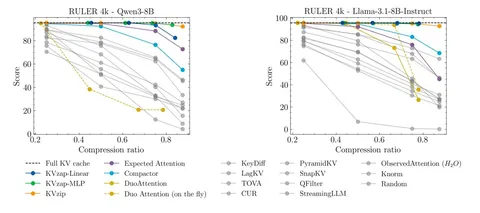
Текущая SOTA для сжатия вдоль размерности T — KVzip, который:
1. получает входной промпт пользователя;
2. просит модель его повторить, аугментируя промпт следующим образом: «user: <input prompt>. Repeat the previous context exactly. assistant: »;
3. для каждой KV-головы для каждого вектора k_i из input prompt запоминают наибольший по длине повторённого промпта вес аттеншна (а в случае GQA максимум берётся и по группе Q-голов);
4. фиксированный процент K_i и v_i, соответствующих наименьшим запомненным весам, удаляются;
5. сжатый промпт подаётся модели.
Во-первых, такая схема скоринга очень дорога. Во-вторых, она применима только к стадии cache prefilling — стадия cache decoding сохраняется целиком. Последняя проблема особенно актуальна в контексте рассуждающих моделей, которые на стадии декодинга генерируют тысячи токенов.
В работе предлагают дистиллировать слегка модифицированные скоры KVzip в легковесный MLP. Для каждого слоя трансформера и каждого входного скрытого состояния MLP предсказывает вектор скоров из H (число KV-голов) компонент, после чего откидываются KV-пары, скоры которых не превосходят некоторый порог. Таким образом, степень сжатия зависит от информативности промпта. Локальный контекст из ближайших 128 токенов, однако, сохраняется полностью. MLP обучается поверх обученной модели на специальном датасете, содержащем целевые скоры KV-пар.
Поскольку MLP не добавляет значительной вычислительной сложности и применяется к входным токенам поточечно, KVzap можно использовать как во время prefilling’a, так и во время декодинга. Сжатие prefilling-стадии также становится дешевле.
Эвалятся авторы на Qwen3-8B, Llama-3.1-8B-Instruct, и Qwen3-32B, KV-кэш удаётся сжать в 2–4 раза при незначительных потерях качества.
@RecSysChannel
Разбор подготовил