Сегодня разберём четыре архитектуры, которые основаны на идее State Space Models (SSM). Одна их них используется в задаче ASR.
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
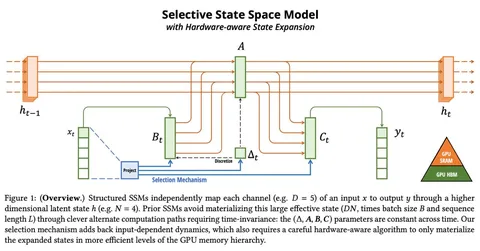
В этой статье авторы развивают идею SSM, дополняя классическую архитектуру «механизмом выбора» (selection mechanism). Анализируя предыдущие работы с SSM-like-архитектурами, авторы приходят к выводу, что именно возможность Mamba отбирать наиболее важные входы (selection in an input-dependent manner) позволяет ей достигать уровня трансформера на задачах моделирования, при этом сохраняя свою линейную сложность.
При анализе современных моделей, работающих с длинным контекстом, авторы делят их на efficient и effective. Первые — быстрые благодаря небольшому state, вторые — с крупным state, способные хранить больше информации. Авторы стремятся найти баланс — сделать обработку быстрой, но при этом сохранить важные детали. Именно для этого и используется selection mechanism.
В базовых SSM матрицы состояний (B и C) имели размер D × N, где D — размерность эмбеддингов, а N — размерность скрытого состояния. Теперь их «развернули во времени» — в новые матрицы состояний добавили новую временную размерность, следовательно, их новый размер — B × L × N. Это дало модели некоторое понимание временного контекста.
В стандартном SSM-подходе свёрточная и рекуррентная модели эквивалентны. Здесь же — свёрточное представление теряется из-за появления input dependency, и возникает сканирование (scan) — матрицы состояния теперь меняются в зависимости от времени.
Mamba-блок получается в результате микса старых и новых идей. Берётся H3-блок — это первый блок в SSM-моделях старого (не input-dependent) подхода, в него добавляется selection mechanism; модифицированный H3-блок миксуют с Gated MLP. Полученные Mamba-блоки впоследствии либо совмещают друг с другом (классическая Mamba), либо смешивают с attention’ом в разных пропорциях. Эти эксперименты описаны в следующих статьях.
Jamba: A Hybrid Transformer-Mamba Language Model
Jamba — попытка смешать Mamba-блоки с attention, получить хорошее качество и большое количество токенов в секунду на гигантском контексте.
В основе — комбинация слоёв: трансформерного, Mamba-слоя и смеси экспертов (MoE). Их стакают в разных пропорциях, лучшим оказывается соотношение 1:7 (на каждый блок трансформера приходится 7 Mamba-блоков); при этом каждый второй из Mamba-блоков — это Mamba-MoE с 16 экспертами.
У Mamba без attention возникали сложности с задачами, где важен жёсткий формат ответа, а также с in-context learning. Jamba решает эти проблемы:
— Mamba-слои и эксперты позволяют работать с длинным контекстом;
— Attention-слой помогает справляться с in-context learning и строгими форматами ответов.
По бенчмаркам, связанным с качеством, Jamba оказывается на уровне Mistral 8x7B, при этом побеждая Llama 2 13B и Llama 2 70B; при этом по пропускной способности Jamba побеждает всех конкурентов с большим перевесом, обеспечивая пропускную способность в 1500 токенов в секунду на контексте 128k.
Даёт Jamba-подход и прирост на бенчмарках на следование формату. В IMDB модель должна отвечать одной из двух категорий: positive или negative. Классическая Mamba не всегда следовала формату и периодически давала случайные ответы, например, «3 из 10». Но при смешивании Mamba с attention эта проблема исчезала — оценка на этих бенчмарках выравнивалась.
Екатерина Козлова