Мы снова выходим на связь — с любопытными постерами продолжающейся ACL.
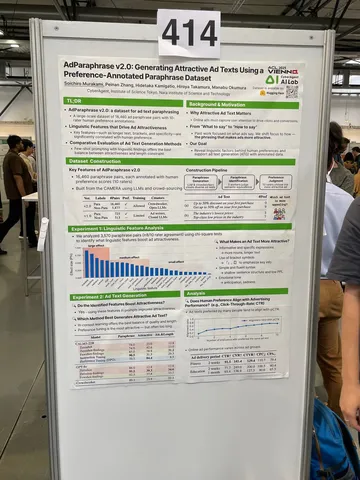
AdParaphrase v2.0: Generating Attractive Ad Texts Using a Preference-Annotated Paraphrase Dataset
Исследователь предлагает набор данных для переформулировок рекламных текстов, содержащий данные о предпочтениях 10 асессоров. Набор позволяет анализировать лингвистические факторы и разрабатывать методы создания привлекательных рекламных текстов.
Утверждают, что анализ продемонстрировал взаимосвязь между предпочтениями пользователей (асессоры) и эффективностью рекламы (CTR). На фото есть график со значимостью исследуемых факторов.
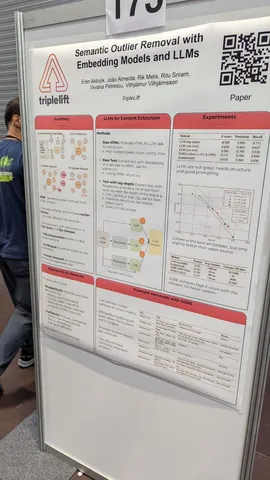
Semantic Outlier Removal with Embedding Models and LLMs
Любопытная прикладная статья о том, как быстро почистить страницу от мусора, не относящегося к основной теме. Берём все HTML-теги с текстом и их уровень вложенности. Отдаём всё это эмбеддеру, а отдельно ему же — тайтл и основную тему. Затем просто режем по расстоянию. Автор статьи утверждает, что такой подход эффективно фильтрует, футеры, меню и тому подобное.
Learning to Insert [PAUSE] Tokens for Better Reasoning
Делая фиктивные паузы и «вздохи» в рассуждениях, модель приходит к лучшим ответам. Авторы изучали возможность улучшения ризонинга за счёт добавления спецтокенов (PAUSE) в процесс обучения LLM. У авторов уже были успешные исследования на эту тему. Конкретно в этой работе представили подход динамического определения позиции для вставки спецтокенов.
Интересное увидели
#YaACL25
Душный NLP