Сегодня начинаем разбирать большой технический репорт (около 40 страниц без аппендикса) от Baidu о том, как они обучали мультимодальные Mixture-of-Experts (MoE)-модели. Авторы предлагают целую линейку моделей: MoE- и dense-версии, с ризонингом и без, варианты под LLM- и VLM-задачи.
В этой части разбираем интересные решения в архитектуре и претрейне.
Архитектура
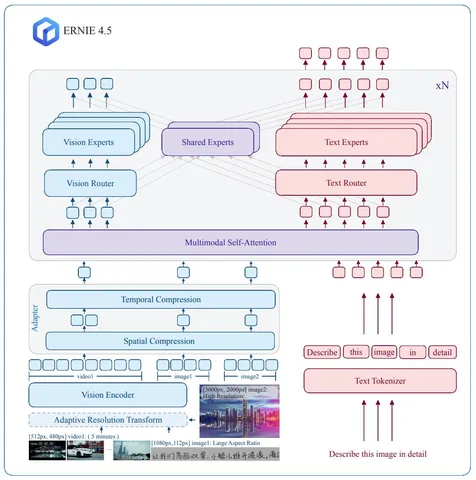
Авторы предлагают мультимодальную гетерогенную MoE-архитектуру. Поддерживаются текст, изображения и видео, на выходе — текст. Внутри блока трансформера два роутера: один маршрутизирует текстовые токены, второй — визуальные.
Кроме специализированных экспертов, есть shared-эксперты, которые всегда активны для обеих модальностей. Это нужно, чтобы не было сдвигов при совместном обучении и модальности не разбегались в эмбеддинговом пространстве (авторы ссылаются на работу Mixture-of-Transformers). Для роутинга используется привычный top-k-подход, знакомый нам по DeepSeek.
Визуальный энкодер реализован аналогично Qwen. С помощью адаптивного 2D RoPE картинку приводят к подходящему разрешению по соотношению сторон, разбивают на патчи и кодируют. Для видео применяют тот же принцип, только с 3D RoPE и таймстемпами.
Если ролик не влезает в контекст, выбираются кадры с нужным шагом (adaptive frame-resolution sampling strategy) и при необходимости уменьшают разрешение. Потом идёт pixel shuffle и темпоральная компрессия — пространственные размеры урезаются, а временная часть остаётся.
В итоге визуальные токены из картинок и видео отправляются в мультимодальный self-attention.
Претрейн
В работе описан стандартный пайплайн с дедупликацией, удалением мусора и quality-фильтрами. Но есть и особенности:
— Data Map: с её помощью данные организуют по языку, домену знаний, сценарию, качеству.
— Human-Model-in-the-Loop Data Refinement: асессоры помогают улучшать качество и разметку, результаты возвращаются в обучение классификаторов.
— Text-only-данные: делятся на пять типов по DIKW-фреймворку; отдельный акцент делается на фактические знания и программирование.
— Interleaved-данные (текст + картинка из веба): аккуратная каталогизация источников, аугментации, чистка, генерация и фильтрация кэпшенов, дедупликация по хешам изображений и текстов; категоризация типов картинок (натуральные сцены, таблицы, скриншоты, чаты, документы и др.).
— Видео: авторы парсили ролики с богатым контекстом, прогоняли через ASR и использовали транскрипты.
— Domain-specific data: здесь используют прогрессивный рефильтринг данных — примерно так же, как это делалось в DeepSeekMath. Собирают пул URL по нужному домену, фильтруют, отправляют на оценку асессором, парсят содержимое, обучают новый классификатор и повторяют цикл.
Интересная находка: авторы собирали сетки из нескольких картинок в один кадр — так модель лучше учится работать с несколькими изображениями сразу и точнее понимает, о каком объекте речь.
Также исследователи пишут о применении REEAO (Record Everything Everywhere All at Once) — способе упаковывать сэмплы так, чтобы максимально заполнять контекст, не теряя остатки, и при этом быть робастными к смене data-parallel-группы.
В следующей части разберём интересное из посттрейна.
Разбор подготовил
CV Time