Сегодня разбираем статью от NVIDIA, в которой высокая скорость достигается в первую очередь за счёт генерации изображений в малое число шагов с приемлемым качеством. Прошлые версии SANA быстро генерировали благодаря VAE с большим downsampling-фактором, а в SANA Sprint добились ещё большего ускорения с помощью дистилляции по шагам.
Основа работы — идея continuous-time consistency моделей, о которой ещё осенью прошлого года говорил Yang Song. По сути, она описывает движение от шума к сигналу через временную производную, превращая дискретный диффузионный процесс в непрерывный поток динамики.
Сontinuous-time consistency позволяет достигать качественных генераций в малое число шагов, но есть и нюанс. Модель должна быть обучена со специальной TrigFlow-параметризацией, а имеющиеся диффузионные модели обычно используют стандартную flow-matching-постановку. Поэтому следующая задача — правильно «перевести» предобученную модель в нужное представление.
SANA-Sprint решает это с помощью серии преобразований:
— переноса временной шкалы в тригонометрические координаты (cos / sin),
— масштабирования латентов, чтобы шум совпадал по дисперсии с данными,
— трансформации выходной head-функции, чтобы предсказания соответствовали формуле consistency-динамики.
Но перенести диффузионку в новую параметризацию — это только половина дела. Вторая часть — заставить всё это стабильно учиться. И вот здесь начинаются инженерные приключения. Стабильность «улетает в космос» из-за того, что временной эмбеддинг использует слишком большой масштаб шума — из-за этого производные становятся огромными. Лечится это просто: нужно изменить масштаб частот эмбеддинга и немного дообучить модель, буквально несколько тысяч итераций.
Вторая проблема — большие нормы градиентов в механизме внимания. Решение довольно стандартное: добавить RMSNorm на Q/K (QK-Normalization) в self- и cross-attention, после чего обучение стабилизируется.
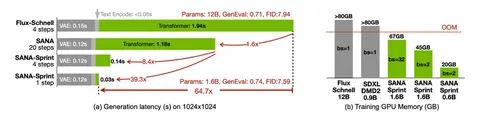
Теперь самое главное — скорость. В разрешении 1024×1024 SANA-Sprint выдаёт картинку за ~0,1–0,18 секунды при одношаговой генерации. Из них на сам трансформер уходит ≈0,03 секунды, остальное — VAE-декодер, который становится основным бутылочным горлышком. По времени работы диффузионной модели SANA-Sprint быстрее FLUX-schnell примерно в 65 раз, а по end-to-end-задержке — примерно в 10 раз. То есть «быстро» тут — не просто эпитет.
Итоговое качество вполне пристойное: на 1–4 шагах она даёт FID и GenEval на уровне или лучше, чем у других быстрых моделей. Например, не уступает FLUX-schnell по метрикам (7,59 против 7,94 по FID и 0,74 против 0,71 по GenEval), будучи заметно быстрее.
Разбор подготовил
CV Time