Авторы этой статьи предлагают новый подход к long-range perception: sparse-voxel-фьюжн камер и лидара с временным контекстом и SSL-предобучением. Всё это и собственный long-range-датасет позволили решению претендовать на SoTA на бенчмарках.
Ключевые фичи:
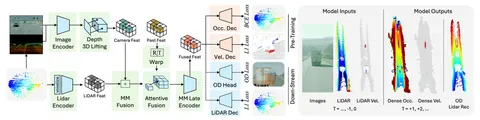
Архитектура решения — на схеме выше. Камерные фичи энкодят отдельно, поднимают в 3D, а затем фьюзят с лидарными. Потом добавляют временной контекст, делают аттеншн и передают в две головы, которые предсказывают occupancy и velocity.
Данных мало — чтобы получить нормальную разметку, нужно гораздо больше. Поэтому авторы собрали собственный датасет из информации о поездках на грузовике с 5 синхронными камерами и 4D-лидаром Aeva (radial speed, 400 м, 10 Гц). Радара не было. Так удалось собрать 60 тысяч кадров, из которых 35 тысяч разметили для детекции.
Image encoder и depth-module обучали вместе. Потом — reconstruction, depth supervision и дистилляционные лоссы фичей. Occupancy- и velocity-голову претрейнили SSL. В конце обучались распознавать объекты.
Результаты впечатляют:
В целом, работа подтверждает: sparse-представления в сочетании с временным контекстом и SSL-предобучением дают заметный выигрыш именно в long-range-сценариях, где BEV-подходы быстро упираются в вычисления и память. Метод выглядит особенно убедительно как практичный компромисс между качеством, дальностью и стоимостью разметки.
Разбор подготовил
404 driver not found