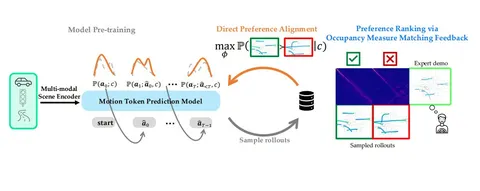
Авторы статьи предложили новый подход к дообучению traffic prediction-моделей без участия человека. Вместо ручной разметки или явной reward-функции они получают скрытые предпочтения (implicit preferences) из экспертных данных (GT).
С помощью distance-функции исследователи измеряют, насколько поведение модели отклоняется от поведения эксперта, и на основе этого ранжируют сгенерированные траектории. В итоге формируются пары более предпочтительных и менее предпочтительных траекторий, по которым обучается модель, увеличивая относительную вероятность «лучших» траекторий по сравнению с базовой (pretrained) моделью.
В качестве distance-функции авторы используют optimal transport на признаковом представлении траекторий — смотрят на разницу между распределениями фич агентов на каждом тике траектории, причём вектора суммируются таким образом, чтобы добиться инвариантности времени — получается распределение фич, которое работает и в будущем, и в прошлом. Фичи агентов извлекаются из траектории путём occupancy measure matching.
Для дообучения модели используется contrastive learning, вдохновлённое DPO, но адаптированное под задачи планирования движения. В отличие от DPO, предпочтения не аннотированы вручную, а определяются по близости траектории к GT (ground truth).
В качестве референсной модели взята Motion LM на 1М, и после дообучения итоговая модель показывает лучшие результаты, чем референсная. При этом на Waymo Open Sim Agents Challenge результаты эксперимента не лучше, чем SOTA больших моделей с размером 10-100М наподобие SMART или BehaviorGPT.
Отдельно авторы показывают, что дообучать модель на парах GT vs generated — это не очень хорошо, потому что, имея дело с траекториями из разных распределений, дискриминатор слишком хорошо выучивает косвенные признаки, например, волнообразность сгенерированной траектории, то есть не то, что нужно для решения задачи.
Разбор подготовил
404 driver not found