Пока беспилотник накатывает часы по дорогам города, он собирает огромный массив информации об окружающем мире и событиях в нём. Каждая система (а в автомобиле их сотни) пишет свои данные. А ещё — умеет поставлять дополнительную информацию о событии, которое описывает. Например, датчик безопасности отправляет водителю предупреждение, а в логи записывает, что причина алерта — неисправность в двигателе или превышение скорости. В итоге, когда машина возвращается на базу, мы получаем огромный, частично размеченный массив данных. Хранить его удобнее в виде структуры, которую грубо можно назвать табличкой.
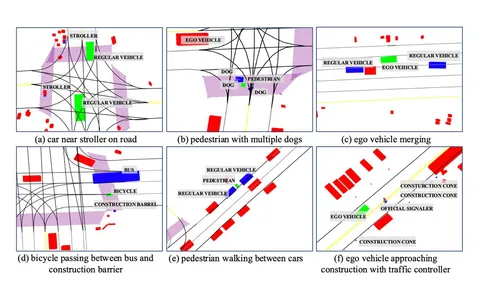
Но как найти в этой табличке данные, действительно интересные для теста, обучения или аналитики? По-настоящему интересных событий среди записей не так уж много. К тому же, иногда требуется отыскать что-то совсем экстравагантное: например, как дети перебрасывают портфель над машинами, или уточка ведёт утят через дорогу и решила отдохнуть на полпути.
В сегодняшней статье авторы пытаются найти «золотые» примеры событий в огромном массиве данных, оперируя полуразмеченым потоком, который записал автомобиль.
Идея в своей основе очень проста — давайте навайбкодим функцию, которая будет проверять, подходит ли нам записанное событие. Для начала авторы попробовали следующий бейзлайн: просили LLM посмотреть в записанные данные и сказать, подходят ли они к запросу с описанием. Подходят — добавляем в датасет, нет — пропускаем.
Эта механика задумывалась как слабая точка для начала, но удивила экспериментаторов тем, что показала отличный результат по восстановлению интересных сцен. Для теста метода использовали вручную размеченные данные.
Окончательный алгоритм посложнее:
1. Руками создать описания функций, которые помогут отфильтровать только подходящие данные из всех записей (например is_speed_limit(all_data)-> bool).
2. Отдать LLM список этих функций и попросить построить из них более сложные — будущие фильтры для строчек из таблицы.
3. Полученной композитной функцией отфильтровать данные. Спойлер: останутся только интересные случаи!
Так авторы собрали RefAV — набор данных из 10 000 различных запросов на естественном языке, которые описывают сложные мультиагентные взаимодействия. Данные о планировании движения получены из 1000 журналов данных, записанных датчиками Argoverse 2.
RefAV можно использовать в качестве тестового датасета для ваших пайплайнов сбора данных: ищите его и код фильтров на Github авторов.
Разбор подготовил
404 driver not found