Часто на складских полках рядом оказываются очень похожие товары. Это приводит к тому, что при сборке заказов товары приходится долго искать: сборщик берёт не то, смотрит, кладёт обратно, продолжает искать нужное. На таких «плохих» полках, где лежат визуально похожие товары (например, шторки одного цвета, но разных моделей) шанс вытащить искомое с первого раза не самый большой. В среднем на поиск нужной позиции теряется 4 секунды. А если таких операций полмиллиона в день, масштабы становятся внушительными.
Екатерина Трофимова, менеджер продуктов в команде логистики Маркета, рассказала, как с помощью LLM получилось оптимизировать хранение товаров на складе с учётом их похожести для более быстрого поиска.
До начала эксперимента у команды не было системного признака схожести товаров — их просто складывали, как придётся. Попробовали сформулировать фановую гипотезу: если системно понимать, какие товары похожи, можно оптимизировать процесс.
Мы применили технологию векторизации текста к названиям товаров, чтобы получить уникальный вектор, описывающий каждый товар. С её помощью считается и сравнивается похожесть того, что кладётся на полку, и того, что уже лежит на ней. Все наименования и метаданные товаров прогнали через YandexGPT и получили вектора, которые легко сравнить и посмотреть косинусную близость между ними. Если значение выше порогового — считаем, что товары слишком похожи и не даём класть их рядом. Если ниже — можно класть на одну полку.
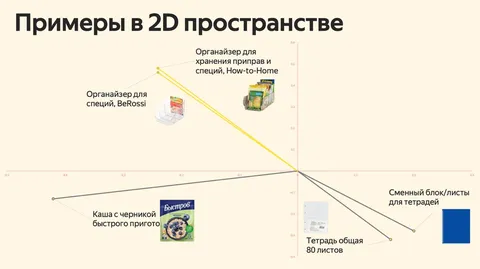
Пример на картинке. Органайзеры для специй разных производителей мы не дадим положить вместе, потому что их вектора очень близки друг к другу. Сменный блок и тетрадь можно положить рядом, потому что у них безопасное пороговое значение, хоть эти вектора тоже находятся относительно близко друг к другу. Каша с черникой могут отправиться как к органайзерам, так и к бумажной продукции.
Помимо LLM, пробовали использовать другие решения, например расстояние Левенштейна (метрика для измерения различий между двумя строками) — но это не сработало. В нашем случае названия товаров могут сильно различаться по форме, даже если они описывают один и тот же продукт, поэтому расстояние Левенштейна будет большим для схожих товаров. GPT справляется с задачей лучше: вектора для таких товаров близки, даже если названия выглядят совсем по-разному.
В среднем, новый подход даёт выигрыш в 2,5 секунды на поиск товара, что приводит к экономии около 2 миллионов рублей в месяц на масштабе всех фулфилментов Маркета. Точность применения метода мы субъективно оцениваем в 7 из 10 — можно было выиграть ещё 1,5 секунды, за счет более агрессивного значения схожести товаров, но чтобы не ловить упячки в духе «кастрюля схожа с вилкой, не клади их вместе», мы ограничились безопасным значением.
Проект работает в проде с июня 2024 года. Мы внедрили его на бэкенде WMS (системы управления складом), и в течение 30 дней после внедрения увидели, что эффект стабильно сохраняется.
Вся реализация решения от проверки гипотезы до внедрения в прод заняла один человеко-месяц разработки. Это подтверждает гипотезу, что не всегда нужно строить космолет — иногда можно сделать быстро, просто и полезно.
Можно сделать вывод, что LLM — это не только генерация, классификация и другие привычные задачи. Иногда стоит взглянуть на модель под другим углом — например, в этом случае её использовали как числовой преобразователь и нашли решение бизнес-задачи.
ML Underhood