Yandex Research везёт пять статей на NeurIPS 2025
Не за горами NeurIPS 2025 — одна из главных конференций в области машинного обучения. Рассказываем о принятых на неё работах исследователей Yandex Research (и не только).
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
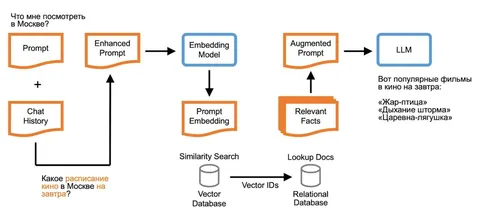
Исследователи предлагают новый подход к ускорению LLM: несколько LLM-агентов запускаются параллельно с возможностью их синхронизации через совместно обновляемый KV-кэш. Реализуется с помощью механизма Hogwild! Inference. Все агенты мгновенно «видят» генерации друг друга и за счёт этого могут пробовать разные способы решения задач, распределять подзадачи между собой, корректировать ошибки друг друга.
Статья получила отметку spotlight — такой статус только у 3% работ, отправленных на NeurIPS.
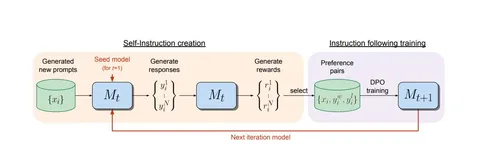
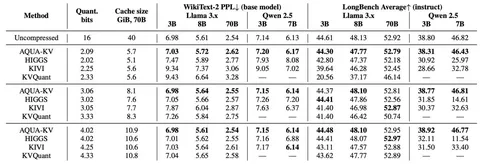
AutoJudge: Judge Decoding Without Manual Annotation
В статье предложили алгоритм майнинга данных для выявления «важных» токенов, влияющих на качество ответа при использовании Speculative Decoding в генерации текста LLM. Метод не требует человеческой разметки и автоматически определяет токены, которые можно безопасно принять, ослабив критерий принятия токенов драфтовой модели, без ухудшения качества ответа.
Авторы обучают компактную модель-классификатор, использующую внутренние представления таргетной и драфтовой LLM для предсказания важности токенов.
Интеграция модели в vLLM повышает скорость генерации текста с использованием Speculative Decoding до 1,5 раз.
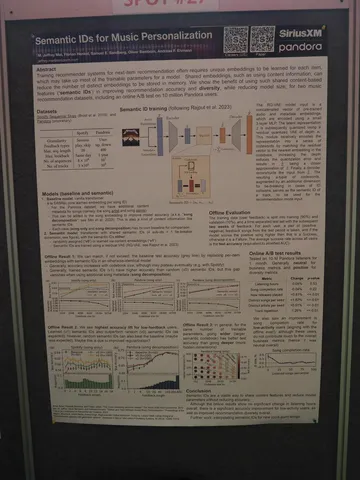
GraphLand: Evaluating Graph Machine Learning Models on Diverse Industrial Data
В ML на графах есть известная проблема с бенчмарками: существующие датасеты покрывают мало доменов, задачи далеки от практики, а в ряде датасетов были допущены ошибки при сборе данных.
Авторы делают шаг к решению этой проблемы: они предлагают GraphLand, бенчмарк из 14 графовых датасетов из различных индустриальных приложений. Некоторые датасеты подготовлены на основании открытых источников, а другие собраны специально для бенчмарка из данных нескольких сервисов Яндекса.
GraphLand позволяет сравнивать графовые модели на широком спектре задач. Графовые нейросети дают хорошие результаты и имеют большой потенциал для использования в индустриальных приложениях. В то же время, существующие графовые фундаментальные модели (Graph Foundation Models) показывают слабые результаты, то есть задача разработки таких моделей ещё далека от решения.
Alchemist: Turning Public Text-to-Image Data into Generative Gold
В статье представили новую методологию создания универсальных наборов данных для файнтюнинга (SFT) моделей преобразования текста в изображение (T2I).
Методология использует предварительно обученную генеративную модель YandexART для оценки эффективных обучающих примеров. С её помощью создали датасет Alchemist, содержащий 3350 пар «картинка-текст» и выложенный в открытый доступ.
Этот датасет значительно улучшает качество генерации пяти общедоступных T2I-моделей, сохраняя при этом разнообразие и следование промпту. Веса дообученных моделей также выложены в открытый доступ.
Подробнее о решении мы писали в телеграм канале CV Time.
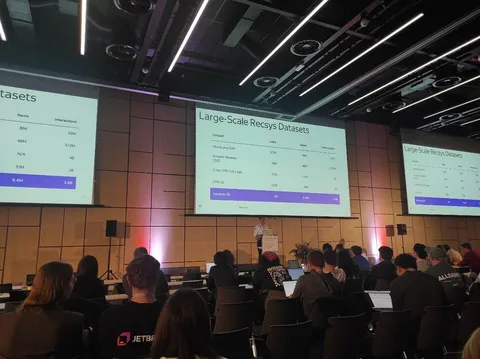
Results of the Big ANN: NeurIPS'23 competition
Статья основана на результатах конкурса Big ANN Challenge, который прошёл в рамках NeurIPS 2023. Его цель — разработка методов векторного поиска (ANN-поиск) в востребованных практико-ориентированных сетапах.
Рассматривались следующие сценарии: векторный поиск с использованием метаданных; поиск, при котором распределения запросов отличается от распределения базы данных (text-to-image); сетап с регулярно обновляющимися базами данных; а также поиск по спарсовым эмбеддингам.
В публикации подробно описываются эти сетапы, наборы данных, метрики и подходы участников, которые показали значительное улучшение точности и эффективности поиска по сравнению с базовыми методами. Результаты дают представление о современных достижениях и направлениях развития в области ANN-поискa.
💫 По традиции инженеры и исследователи Яндекса поедут на конференцию и будут делиться самым интересным.
#YaNeurIPS25
ML Underhood
Не за горами NeurIPS 2025 — одна из главных конференций в области машинного обучения. Рассказываем о принятых на неё работах исследователей Yandex Research (и не только).
Hogwild! Inference: Parallel LLM Generation via Concurrent Attention
Исследователи предлагают новый подход к ускорению LLM: несколько LLM-агентов запускаются параллельно с возможностью их синхронизации через совместно обновляемый KV-кэш. Реализуется с помощью механизма Hogwild! Inference. Все агенты мгновенно «видят» генерации друг друга и за счёт этого могут пробовать разные способы решения задач, распределять подзадачи между собой, корректировать ошибки друг друга.
Статья получила отметку spotlight — такой статус только у 3% работ, отправленных на NeurIPS.
AutoJudge: Judge Decoding Without Manual Annotation
В статье предложили алгоритм майнинга данных для выявления «важных» токенов, влияющих на качество ответа при использовании Speculative Decoding в генерации текста LLM. Метод не требует человеческой разметки и автоматически определяет токены, которые можно безопасно принять, ослабив критерий принятия токенов драфтовой модели, без ухудшения качества ответа.
Авторы обучают компактную модель-классификатор, использующую внутренние представления таргетной и драфтовой LLM для предсказания важности токенов.
Интеграция модели в vLLM повышает скорость генерации текста с использованием Speculative Decoding до 1,5 раз.
GraphLand: Evaluating Graph Machine Learning Models on Diverse Industrial Data
В ML на графах есть известная проблема с бенчмарками: существующие датасеты покрывают мало доменов, задачи далеки от практики, а в ряде датасетов были допущены ошибки при сборе данных.
Авторы делают шаг к решению этой проблемы: они предлагают GraphLand, бенчмарк из 14 графовых датасетов из различных индустриальных приложений. Некоторые датасеты подготовлены на основании открытых источников, а другие собраны специально для бенчмарка из данных нескольких сервисов Яндекса.
GraphLand позволяет сравнивать графовые модели на широком спектре задач. Графовые нейросети дают хорошие результаты и имеют большой потенциал для использования в индустриальных приложениях. В то же время, существующие графовые фундаментальные модели (Graph Foundation Models) показывают слабые результаты, то есть задача разработки таких моделей ещё далека от решения.
Alchemist: Turning Public Text-to-Image Data into Generative Gold
В статье представили новую методологию создания универсальных наборов данных для файнтюнинга (SFT) моделей преобразования текста в изображение (T2I).
Методология использует предварительно обученную генеративную модель YandexART для оценки эффективных обучающих примеров. С её помощью создали датасет Alchemist, содержащий 3350 пар «картинка-текст» и выложенный в открытый доступ.
Этот датасет значительно улучшает качество генерации пяти общедоступных T2I-моделей, сохраняя при этом разнообразие и следование промпту. Веса дообученных моделей также выложены в открытый доступ.
Подробнее о решении мы писали в телеграм канале CV Time.
Results of the Big ANN: NeurIPS'23 competition
Статья основана на результатах конкурса Big ANN Challenge, который прошёл в рамках NeurIPS 2023. Его цель — разработка методов векторного поиска (ANN-поиск) в востребованных практико-ориентированных сетапах.
Рассматривались следующие сценарии: векторный поиск с использованием метаданных; поиск, при котором распределения запросов отличается от распределения базы данных (text-to-image); сетап с регулярно обновляющимися базами данных; а также поиск по спарсовым эмбеддингам.
В публикации подробно описываются эти сетапы, наборы данных, метрики и подходы участников, которые показали значительное улучшение точности и эффективности поиска по сравнению с базовыми методами. Результаты дают представление о современных достижениях и направлениях развития в области ANN-поискa.
#YaNeurIPS25
ML Underhood
1 751 просмотров · 59 реакций
Открыть в Telegram · Открыть пост на сайте