Яркие истории о разработках Яндекса в 2024 году
За минувший год ML’щики Яндекса сделали много интересного, и о многом мы писали в нашем канале. Перед вами небольшая ретроспектива — предлагаем вспомнить разработки и улучшения в продуктах за 2024 год.
Библиотека YaFSDP
Блиц-интервью с руководителем службы претрейна YandexGPT Михаилом Хрущевым. Узнали много интересного о библиотеке YaFSDP, которая ускоряет обучение больших языковых моделей.
Как устроен YandexART, YandexART 1.3 и генерация видео в Шедевруме
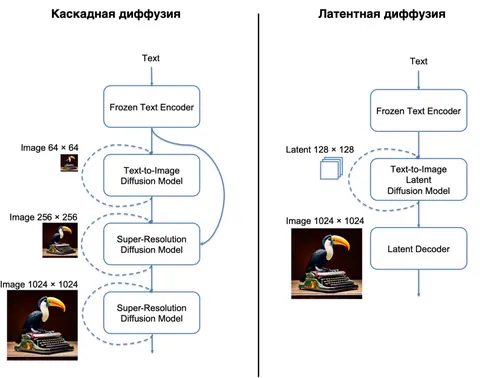
Сразу три поста о прекрасном — об искусстве. Первый — о мультимодальной модели для генерации изображений YandexART в целом. Второй — о новой версии нейросети, основанной на латентной диффузии, что позволяет здорово экономить вычислительные ресурсы. Третий пост вышел в сентябре — аккурат под костры рябин. В публикации речь идет об улучшенной генерации видео в Шедевруме. Рассказали, как она устроена и как обучали модель.
Как работает Нейро
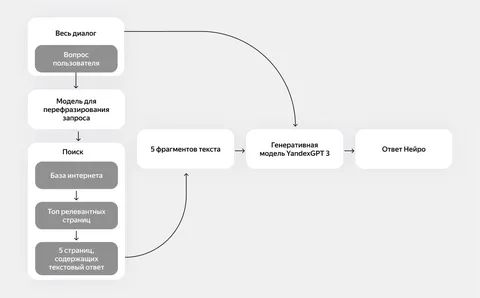
Весной Яндекс запустил сервис для поиска ответов на вопросы, заданные на естественном языке — Нейро. Под капотом у него, разумеется, LLM. А как модель себя проявляет — читайте в этом кулинарном посте с сакраментальным вопросом: «А какие же щи без капусты?»
Алиса на казахском языке, локальный ASR в Яндекс Станции и эхоподавление
Три поста о голосовом ассистенте Яндекса. Первый рассказывает, как Алису учили говорить на казахском языке. Архитектура здесь схожа с той, что и у русскоязычного ассистента, однако есть свои тонкости. Подробно рассказали о них в самом лингвистически заряженном посте года.
Второй пост — о создании локальной системы автоматического распознавания речи в Станции. Технические возможности колонки накладывают на разработчиков ограничения, с которыми приходится мириться. Об этом (и многом другом) и рассказали.
Третий пост об эхоподавлении (AEC). Рассказываем, как оно устроено, а заодно о новом бета-датасете, на котором инженеры перебирали гиперпараметры, чтобы добиться улучшения качества.
OmniCast в погоде
OmniCast — новая технология, принятая на вооружение Яндекс Погодой. Она позволяет точно предсказывать осадки и циклоны, используя данные как с профессиональных, так и с любительских метеостанций.
Улучшенный фотоперевод
Осенью мы обновили фотоперевод — теперь понимать зарубежные мемы, распечатанные на бумаге (бывает и такое), совсем просто. Новая модель лучше выделяет семантические блоки, а переведённый текст стал больше похож на оригинальный благодаря алгоритму затирания. О том, что и как ещё изменилось — рассказываем в посте.
ML Underhood
За минувший год ML’щики Яндекса сделали много интересного, и о многом мы писали в нашем канале. Перед вами небольшая ретроспектива — предлагаем вспомнить разработки и улучшения в продуктах за 2024 год.
Библиотека YaFSDP
Блиц-интервью с руководителем службы претрейна YandexGPT Михаилом Хрущевым. Узнали много интересного о библиотеке YaFSDP, которая ускоряет обучение больших языковых моделей.
Как устроен YandexART, YandexART 1.3 и генерация видео в Шедевруме
Сразу три поста о прекрасном — об искусстве. Первый — о мультимодальной модели для генерации изображений YandexART в целом. Второй — о новой версии нейросети, основанной на латентной диффузии, что позволяет здорово экономить вычислительные ресурсы. Третий пост вышел в сентябре — аккурат под костры рябин. В публикации речь идет об улучшенной генерации видео в Шедевруме. Рассказали, как она устроена и как обучали модель.
Как работает Нейро
Весной Яндекс запустил сервис для поиска ответов на вопросы, заданные на естественном языке — Нейро. Под капотом у него, разумеется, LLM. А как модель себя проявляет — читайте в этом кулинарном посте с сакраментальным вопросом: «А какие же щи без капусты?»
Алиса на казахском языке, локальный ASR в Яндекс Станции и эхоподавление
Три поста о голосовом ассистенте Яндекса. Первый рассказывает, как Алису учили говорить на казахском языке. Архитектура здесь схожа с той, что и у русскоязычного ассистента, однако есть свои тонкости. Подробно рассказали о них в самом лингвистически заряженном посте года.
Второй пост — о создании локальной системы автоматического распознавания речи в Станции. Технические возможности колонки накладывают на разработчиков ограничения, с которыми приходится мириться. Об этом (и многом другом) и рассказали.
Третий пост об эхоподавлении (AEC). Рассказываем, как оно устроено, а заодно о новом бета-датасете, на котором инженеры перебирали гиперпараметры, чтобы добиться улучшения качества.
OmniCast в погоде
OmniCast — новая технология, принятая на вооружение Яндекс Погодой. Она позволяет точно предсказывать осадки и циклоны, используя данные как с профессиональных, так и с любительских метеостанций.
Улучшенный фотоперевод
Осенью мы обновили фотоперевод — теперь понимать зарубежные мемы, распечатанные на бумаге (бывает и такое), совсем просто. Новая модель лучше выделяет семантические блоки, а переведённый текст стал больше похож на оригинальный благодаря алгоритму затирания. О том, что и как ещё изменилось — рассказываем в посте.
ML Underhood
2 954 просмотров · 22 реакций
Открыть в Telegram · Открыть пост на сайте