На прошлой неделе мы запустили агент «Исследовать» в Алисе AI, а сегодня делимся техническими деталями
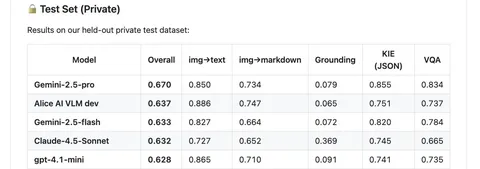
Это DeepResearch-агент, который может проанализировать большой объём данных и выдать полноценный разбор темы. За три месяца тестирования «Исследовать» использовали более 280 тысяч раз. Техлид агента Прохор Гладких рассказал о нём подробнее.
А работа началась год назад — в апреле 2025-го. Первая версия представляла собой классический пайплайн: поиск и генерация. Однако запросы в поиск генерировали с помощью тяжёлой модели и сразу несколько, а ответы получали с помощью ризонера. Так в Алисе появился режим «рассуждать + поиск».
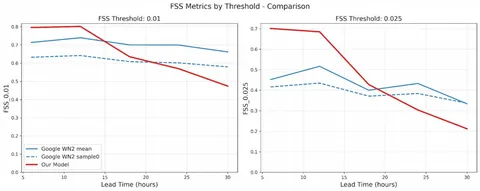
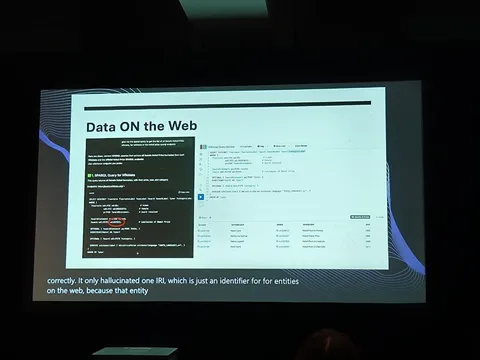
Первый прототип непосредственно агента «Исследовать» был аналогом CodeAgent, собранным из smolagents. Такой подход позволил добиться неплохих результатов на SimpleQA и Frames.
Вторая итерация агента уже была полностью реализована на классическом function calling.
Удалось побить метрики CodeAgent и полностью отказаться от написания кода для вызова тулов. Всего в «Исследовать» 13 подагентов и 9 тулов, среди которых, например, CodeSandbox для запуска сгенерированного агентом кода.
Попробовать агент «Исследовать» можно на сайте alice.yandex.ru, в приложениях Алиса AI, Яндекс с Алисой AI и в Яндекс Браузере.
ML Underhood
Это DeepResearch-агент, который может проанализировать большой объём данных и выдать полноценный разбор темы. За три месяца тестирования «Исследовать» использовали более 280 тысяч раз. Техлид агента Прохор Гладких рассказал о нём подробнее.
А работа началась год назад — в апреле 2025-го. Первая версия представляла собой классический пайплайн: поиск и генерация. Однако запросы в поиск генерировали с помощью тяжёлой модели и сразу несколько, а ответы получали с помощью ризонера. Так в Алисе появился режим «рассуждать + поиск».
Первый прототип непосредственно агента «Исследовать» был аналогом CodeAgent, собранным из smolagents. Такой подход позволил добиться неплохих результатов на SimpleQA и Frames.
Вторая итерация агента уже была полностью реализована на классическом function calling.
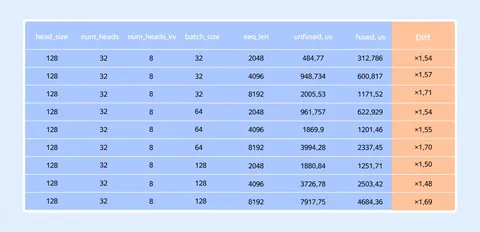
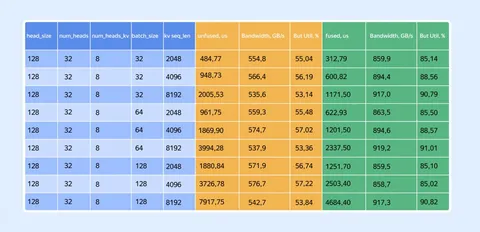
DeepResearch — и у нас, и у конкурентов — сильно нагружающий GPU продукт. Здесь очень важна оптимизация потребления ресурсов видеокарт, так как на один запрос пользователя агент делает сотни вызовов моделей. Крайне важно попадать в KV-cache, и чтобы его объёма хватало на все параллельные исследования в поде.
Чтобы этого достичь, мы сделали систему, которая отправляет все запросы в рамках одного исследования на один под, а также провели около 30 экспериментов по подбору параметров LLM-движка. В итоге достигли оптимизации в десятки раз, что позволило раскатить агента на всех пользователей.
Удалось побить метрики CodeAgent и полностью отказаться от написания кода для вызова тулов. Всего в «Исследовать» 13 подагентов и 9 тулов, среди которых, например, CodeSandbox для запуска сгенерированного агентом кода.
Я был сильно удивлён, что агент отлично справляется не только с научными запросами, но и с подбором товаров в маркетплейсах по моим сложным критериям. Особенно порадовало, что он вычитывает отзывы пользователей и анализирует их за меня. Почти все покупки я сейчас делаю с помощью агента «Исследовать» для выбора и агента «Найти дешевле» для поиска лучшего предложения. Это снимает с меня когнитивную нагрузку по выбору бренда, отсмотру отзывов и так далее.
Попробовать агент «Исследовать» можно на сайте alice.yandex.ru, в приложениях Алиса AI, Яндекс с Алисой AI и в Яндекс Браузере.
ML Underhood
2 577 просмотров · 31 реакций
Открыть в Telegram · Открыть пост на сайте