When to Retrain Machine Learning Model
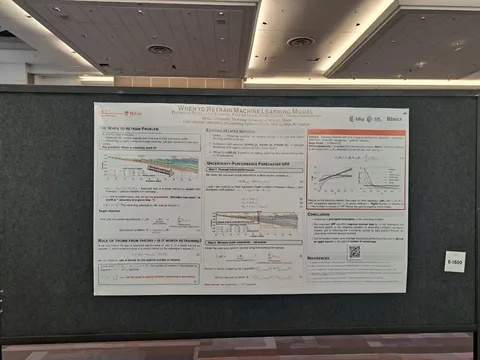
В работе исследуют проблему регулярного переобучения моделей в продакшн-системах: то, как часто нужно полностью обучать модель с нуля на новых данных. Приходят к выводу, что переобучать слишком часто — дорого и бесполезно, попробуют понять, в какие моменты времени это лучше делать. Получается временной ряд, который они аппроксимируют своими методами. Решение имеет смысл, только если есть возможность переобучать модель очень часто, но хочется делать это реже — без ущерба для качества. При этом, поскольку подход ориентирован именно на полное переобучение «с нуля», он не применяется к онлайн-обучению: там всегда предпочтительнее дообучать модель настолько часто, насколько это возможно.
How to set AdamW’s weight decay as you scale model and dataset size
Новый метод для подбора гиперпараметра регуляризации в AdamW. Авторы переписали формулы weight decay в виде, который начинает походить на экспоненциальное сглаживание (EWMA). Репараметризуют его новыми параметрами и говорят, что подбор одного нового параметра работает проще и сохраняет свойства при изменении размеров датасета, размера батча или размера архитектуры. То есть можно один раз подобрать и какое-то время о нём не вспоминать. Формула очень простая и её будет легко попробовать в боевых моделях.
Efficient Optimization with Orthogonality Constraint: a Randomized Riemannian Submanifold Method
Ещё одна статья на тему оптимизации на римановых многообразиях для ортогональных матриц. Из интересного — оказывается, условия ортогональности используются сейчас не только в классических задачах вроде PCA, но и в некоторых задачах файнтюна. К сожалению, автор не читал статью Orthogonal Weight Normalization, где в 2017 году была предложена простая и вычислительно эффективная идея, хорошо зарекомендовавшая себя на практике. Было бы круто сравнить эти подходы на одной задаче.
Интересное отобрал
ML Underhood
#YaICML25