На ICML 2025 команда Yandex Research представила шесть статей (каких именно — читайте в одном из предыдущих постов) — среди них есть работа, посвящённая методу адаптивной квантизации KV-кэша. Один из авторов, исследователь Yandex Research Алина Шутова, рассказала нашему каналу, в чём суть предложенного в публикации способа.
Одна из ключевых проблем эксплуатации LLM — экспоненциальный рост потребления памяти графических процессоров при обработке длинных контекстов. Это связано с необходимостью хранения KV-кэша. Для современных моделей, таких как Llama 3.2 70B, и контекстов в 131 тысячу токенов, объём KV-кэша может достигать 42,9 ГБ на последовательность, что существенно ограничивает практическое применение и увеличивает стоимость вычислений. Традиционные методы сжатия, такие как примитивное квантование или прунинг, демонстрируют значительную деградацию качества генерации при агрессивных режимах сжатия, особенно в области 2–3 бит на значение.
Предложенный авторами статьи метод AQUA-KV (Adaptive QUAntization for Key-Value) представляет принципиально новый подход, основанный на фундаментальном наблюдении: векторы ключей и значений в соседних слоях трансформера обладают высокой степенью корреляции. Эта структурная избыточность позволяет прогнозировать значительную часть информации слоя k+1 на основе данных слоя k.
Вместо независимого квантования каждого слоя AQUA-KV использует обученные линейные предикторы. Один предиктор предсказывает ключи слоя k+1 на основе ключей слоя k, другой предсказывает значения слоя k+1 по комбинации предсказанных ключей этого слоя и значений слоя k. Обучение этих компактных адаптеров проводится в ходе одноразовой калибровки на целевой модели.
Критический шаг метода — переход от квантования векторов целиком к квантованию только остаточной информации, то есть разности между фактическими векторами слоя и их предсказаниями. Поскольку остаток содержит лишь ту информацию, которую нельзя получить из предыдущего слоя, его информационная энтропия существенно ниже. Эта остаточная компонента подвергается экстремальному квантованию (до 2–2,5 бит на элемент) с применением векторного квантования без данных (data-free VQ), адаптивно оптимизирующего распределение битов под дисперсию остатков. Для восстановления KV-векторов во время инференса используются те же предикторы и деквантованный остаток.
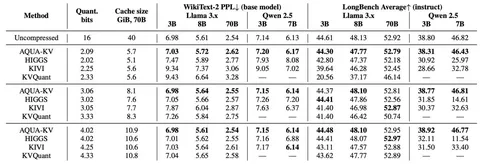
Эксперименты демонстрируют эффективность AQUA-KV. На моделях семейств Llama 3.2 и Qwen 2.5 применение метода с квантованием до 2 бит на значение привело к снижению объёма памяти KV-кэша в 16 раз (с ~43 ГБ до ~2,7 ГБ для контекста в 131K токенов) при сохранении практически исходного качества генерации. Относительное увеличение перплексии составило менее 1%, а деградация точности на задачах длинного контекста из бенчмарка LongBench не превысила 1%. AQUA-KV совместим с любыми методами квантизации, и, как продемонстрировано в работе, заметно улучшает качество всех рассмотренных методов. Метод демонстрирует совместимость с техниками прунинга, такими как H2O, обеспечивая дополнительную экономию памяти. Код AQUA-KV можно найти на GitHub.
ML Underhood
#YaICML25