Важная задача отдела картопроизводства — улучшать качество детекции дорожных знаков. Один из способов — находить знаки на панорамах, снятых с помощью телефонов или камер безопасности в такси. На момент старта проекта детектор знаков уже был, но он находил не все знаки и с недостаточной полнотой и точностью.
Сами по себе знаки можно взять хоть из Википедии — там есть список всех 300+ штук. Но модель не тренируется на списке — нужны десятки тысяч изображений с примерами каждого знака в реальных условиях. Вот тут и начинается основная работа.
Пайплайн, описанный ниже, служит для сужения огромного набора снимков (сотни миллионов) до относительно небольшого (сотни тысяч), на которых присутствует искомый нами знак.
1. Находим всё, что может быть знаком
На имеющемся датасете обучили RT-DETR на единственный класс «дорожный знак». Он «выкручен в полноту»: то есть в трейдофе полнота <-> точность, выбрана именно полнота. Так сделано, потому что предсказания этого детектора — кандидаты на проверку. На выходе из этого этапа получается много «кропов-кандидатов» — кусочков исходного снимка, на котором представлено что-то похожее на знак.
2. Классификация кропов
Дальше в дело вступает few-shot-классификатор на основе нашей картиночной тушки — большой свёрточной сети, которую разрабатывает Служба компьютерного зрения. Из неё взяты «эмбединги похожих» — представление изображений в векторном пространстве, где похожие изображения переходят в близкие вектора. Поверх этих эмбедингов обучены несколько линейных слоёв. В качестве примеров позитивного класса используются 20–30 примеров нужного нам знака. Примеров негативного класса в избытке — их берут из текущего датасета дорожных знаков. В результате получается блок, который умеет отвечать: похоже ли входное изображение (кроп-кандидат) на искомый нами знак.
3. Классификация снимков
Если хотя бы один кроп на снимке прошёл классификацию, мы сохраняем весь снимок. Так из сотен миллионов остаётся от сотни тысяч до миллиона в зависимости от знака. Из полученных кандидатов мы отбираем на разметку лишь малое количество: 2–5–10 тысяч картинок.
Дальше подключается трёхступенчатый пайплайн разметки с помощью людей в Яндекс Заданиях.
1. Проверка наличия знака
Асессор отвечает, есть ли на изображении нужный знак («да», «нет», «не загрузилась картинка»). Это быстрый и дешёвый способ отсеять ошибки предыдущих этапов, не тратя ресурсы на полную разметку ненужных картинок. Чтобы на выходе получить, например, 1200 знаков, на вход подаём с запасом — 2000–3000 изображений, иногда больше, если знак редкий.
2. Разметка всех знаков
На оставшихся изображениях люди размечают прямоугольники вокруг всех дорожных знаков — не только искомого. Это важно для обучения детектора: нужны как положительные примеры, так и фоны с другими знаками, чтобы избежать ложных срабатываний.
3. Классификация каждого знака
Каждый размеченный знак показывается отдельно, и асессор выбирает, что это за знак — из палетки с 300+ вариантов. Пробовали упрощать интерфейс (группировка по цвету, форме и прочему), но это всё равно остаётся самым трудоёмким этапом.
Что в итоге
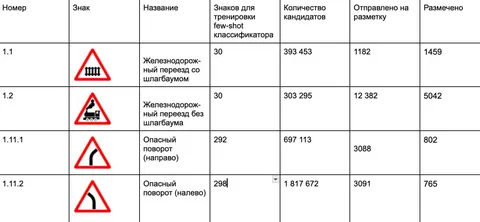
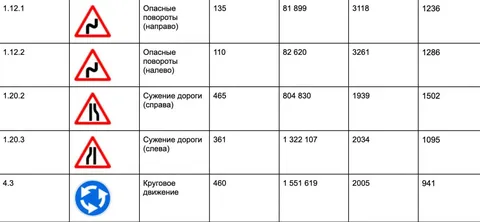
Сейчас весь пайплайн уже работает в проде. Для некоторых знаков, вроде «железнодорожный переезд», удалось собрать 5000 размеченных примеров — больше, чем требовалось. А вот со знаками поворота всё сложнее: классификатор часто путает «влево» и «вправо», из-за чего нужные картинки отсеиваются, и на выходе остаётся по 700–800 примеров. В ближайший месяц планируем дособрать все основные знаки по России и двинуться в сторону подготовки датасетов в межнаре.
ML Underhood