Сегодня разберём статью о том, как научить языковую модель самостоятельно оценивать качество своих ответов и итеративно улучшаться за счëт этого.
Direct Preference Optimization (DPO)
Раньше большие языковые модели учили примерно так:
1. Предобучение без учителя на огромном корпусе текстов;
2. SFT — supervised fine-tuning;
3. Создание датасета предпочтений (сравнение качества нескольких гипотез LLM между собой вручную);
4. Обучение reward-модели на датасете предпочтений.
5. RL — reinforcement learning.
Метод DPO (Direct Preference Optimization) предлагает заменить обучение reward-модели и RL на supervised fine-tuning LLM на датасете предпочтений с некоторой лосс-функцией (подробнее в оригинальной статье про DPO).
Метод авторов статьи
Авторы предлагают учить LLM не только отвечать на вопросы пользователя (instruction following), но и оценивать эти ответы с помощью механизма LMM-as-a-Judge. Благодаря этому можно автоматизировать создание датасета предпочтений.
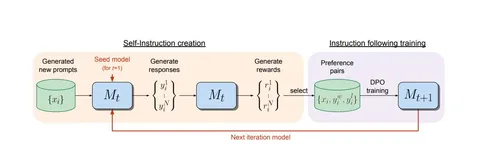
Более подробно, взяв предобученную модель M₀, делают еë supervised fine-tuning на instruction following (IFT данные) + оценивание качества ответа (EFT данные) — и так получают модель M₁. Далее начинается итеративный процесс, при котором:
1. Модель Mᵢ сама генерирует датасет предпочтений (генерирует гипотезы и оценивает их) обозначаемый AEFT(Mᵢ);
2. Модель Mᵢ дообучается на AEFT(Mᵢ) с помощью DPO — так получаем новую модель Mᵢ₊₁.
Весь процесс выглядит так:
M₀ — предобученная LLM без fine-tuning.
M₁ — модель, инициализированная M₀, а после дообученная на IFT+EFT в режиме supervised fine-tuning.
M₂ — модель, инициализированная M₁ и дообученная на AEFT(M₁) в режиме DPO.
M₃ — модель, инициализированная M₂ и дообученная на AEFT(M₂) в режиме DPO.
Авторы утверждают, что метод не только помогает нейросетям лучше справляться с инструкциями, но и улучшает их способности к оцениванию ответов. Доработав Llama 2 70B на трёх итерациях этого подхода, они получили модель, которая превосходит многие существующие системы в таблице лидеров AlpacaEval 2.0: например, Claude 2, Gemini Pro и GPT-4 0613.
Более подробно итерации обучения, применяемые в подходе, описали в канале «Душный NLP».
Разбор подготовил
ML Underhood