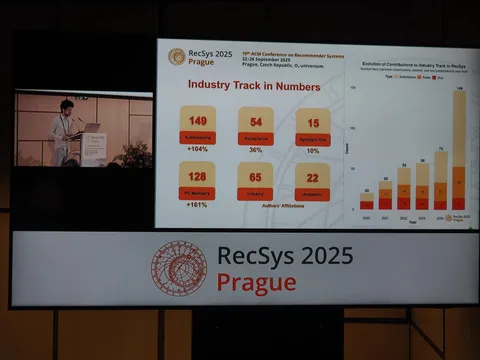
Конкуренция на индустриальном треке растёт: +104% сабмитов к предыдущему году. Всё, что выделил из этого многообразия работ Иван Романов, — читайте ниже.
Всё чаще звучало слово latency. Даже keynote оказался практичным: Jure Leskovec (именитый профессор из Стэнфорда) прорекламировал свой стартап Kumo — AutoML на графовых нейросетях с SQL-подобным языком для fit-predict по таблицам. Мне запомнился «наброс», что существует опенсорс-решение (CARTE: Pretraining and Transfer for Tabular Learning), которое из коробки даёт аналогичные результаты.
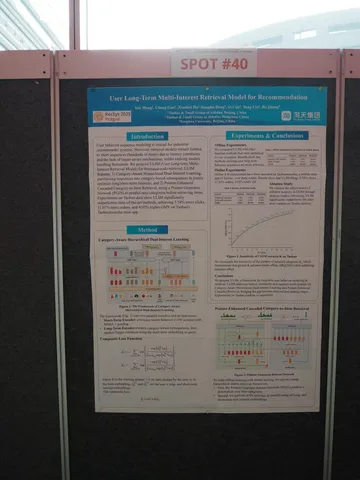
Следующая статья зацепила названием — User Long-Term Multi-Interest Retrieval Model for Recommendation. В качестве MLA-ментора предстоит «забустить» одну рексистему с помощью long-term-интересов. Явно разделяют долгосрочное и краткосрочное поведение пользователя и на вход долгосрочного энкодера передают в качестве query (как в encoder-decoder) выход краткосрочного. Обучают на два лосса. Кстати, заметен общий тренд: почти в каждой индустриальной статье используют несколько лоссов.
Не менее полезная статья — Zero-shot Cross-domain Knowledge Distillation: A Case Study on YouTube Music. Проблема: нужно запустить рексистему с нуля (YouTube Music), но уже есть готовая (на главной YouTube) с пересечением по фичам. Решение: переиспользовать веса, добавить спецтокены для новых фичей и дистиллировать артефакты от старой модели. Да, есть элемент overengineering, но главное — в индустрии начинают трогать cross-domain, и результаты уже позитивные.
Похожую проблему решают ребята из академии — LM-RecG: A Semantic Bias-Aware Framework for Zero-Shot Sequential Recommendation. Деталей в статье намного больше, но трудно сказать, что из этого работает (на академических датасетах буст настолько большой, что верится с трудом).
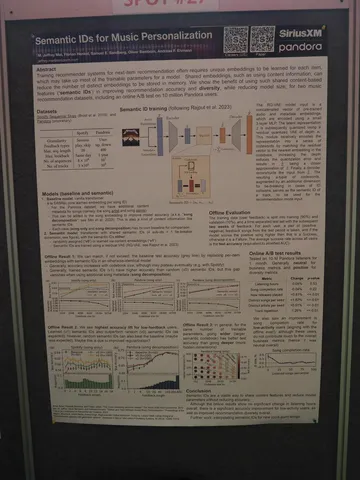
Было сразу три статьи, которые решают проблему использования контентных фичей в рекомендациях. Подходы разные, но суть одна: инициализировать lookup table через предобученную модель, а поверх запускать последовательную модель на айдишниках.
«Внебрачное дитя» европейских регуляций и Google — Cross-Batch Aggregation for Streaming Learning from Label Proportions in Industrial-Scale Recommendation Systems. Нельзя однозначно определить связь user-item, поэтому используют трюк из Learning from Label Proportions. Автор признал, что не знал о такой задаче до написания статьи, но был рад, что «поле уже немного пропахано».
Scaling Generative Recommendations with Context Parallelism on Hierarchical Sequential Transducers: инженерное ускорение HSTU (AllGather меняют на AllToAll, кастомные Triton-кернелы, jagged tensors — аналог NestedTensor из PyTorch в TorchRec). Около постера никого не было, визуализации классные, но темой вокруг особо не интересовались, хотя ускорение достойное — x5.
T2ARec: The Proposed Method — по метрикам отлично, но пугает SSM (state space model). Основное улучшение достигается через test-time alignment (во время теста модели выполняется градиентный спуск по двум вспомогательным задачам: сопоставление временных интервалов пользователей и сопоставление previous state с current state представления).
В конце дня был «званый ужин», на котором Иван успел посидеть за тремя русскоговорящими столами и вынести кое-какие инсайты:
— По ощущениям 2/3 участников используют GPT-интерфейс (VSCode, Cursor, либо разделённый экран: с одной стороны Jupyter Notebook, с другой — Perplexity/Gemini).
— У самого в квартальных целях — порешать эту проблему, так что, наверное, я biased, но повсюду говорят о холодном старте.
— С Сашей Петровым (gSASRec) обсуждали формулу хорошей статьи. Я уточнил, не обидится ли он на фидбек, что «читается просто». Его ответ порадовал: «Чем проще читается статья, тем сложнее её было писать».
ML Underhood