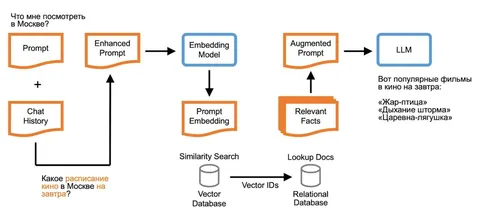
Сегодня команда Yandex B2B Tech представила новую версию системы управления базами данных YDB. Главная фича — векторный поиск. С ним можно за миллисекунды находить информацию в разнородных данных и формировать персональные ответы на запросы пользователей.
Технология основана на поиске семантически похожих данных в больших коллекциях. Разные типы данных — текст, изображения, аудио и видео — представляются в виде эмбеддингов, которые затем сохраняются в базу данных. После этого можно находить не только точные совпадения, но и близкие по смыслу объекты — даже если они записаны по-разному или вообще без описаний.
Векторный поиск улучшает качество и увеличивает скорость работы продуктов на базе ИИ: рекомендательных и поисковых систем, виртуальных ассистентов. Никита Зубков, руководитель отдела разработки диалоговой системы Алисы, рассказал, как технология помогает сделать общение пользователей с ассистентом более персонализированным:
С помощью векторного поиска мы находим наиболее релевантные диалогу сессии в прошлом и подставляем их в контекст. Благодаря этому ответы Алисы становятся персональными: она больше не забывает, как зовут вашего котика, когда вы последний раз ходили в спортзал или какой фильм вы недавно обсуждали с друзьями.
Например, раньше Алиса обнулялась и не помнила, есть ли у вас домашнее животное, какой оно породы и как его зовут. Но теперь, если сообщить ей эту информацию, а затем задать вопрос: «Как мне провести выходные?», она может предложить пойти в парк с собакой и даже напомнит взять любимый зелёный мячик питомца.
В YDB есть две версии векторного поиска: точный и приближённый. Первый гарантирует, что найденные результаты будут самыми похожими на использованный образец, но требует большой вычислительной сложности. Приближённый — позволяет искать по коллекциям из сотен миллионов векторов за десятки-сотни миллисекунд, даже если все вектора не помещаются в оперативную память.
База данных YDB доступна как опенсорс-проект и как коммерческая сборка с открытым ядром. Обе версии можно развернуть на своих серверах или воспользоваться managed-решением в Yandex Cloud. Больше технических деталей можно узнать из статьи на Хабре.
ML Underhood