Продолжаем рассказывать о самых интересных статьях с конференции и показываем один весьма экстравагантный стенд.
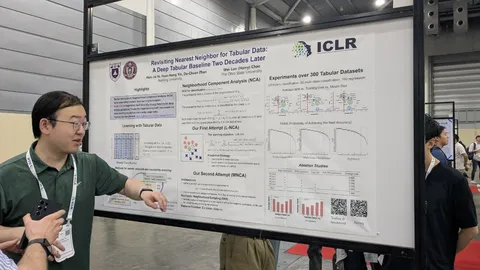
Revisiting Nearest Neighbor for Tabular Data: A Deep Tabular Baseline Two Decades Later
Авторы улучшили NCA (непараметрический метод на основе nearest neighbour) простыми нейросетями и обогнали бустинги и TabularDL на многих задачах.
Результаты:
— На наборе задач мульти-классификации их метод оказался лучшим на 20% задач, что на 7 процентных пункта больше, чем с Топ-2 подходом (у TabR 13%)
— Для бинарной классификации и регрессии результаты, скорее, сравнимы с текущими SOTA.
— Применялись на задачах с сотнями (но не тысячами) фичей.
Приёмы:
— Отказ от LBFGS в NCA в пользу SGD для обучения проектора.
— Стохастика и по батчам, и по соседям — сэмплируются случайные группы соседей одного класса/
— Заменили линейную проекцию из NCA на нелинейную. Используют простую нейросеть (2-3 слоя, BN, ReLU)/
— От предсказания жёстких меток класса перешли к вероятностям за счёт softmax, чтобы сгладить задачу оптимизации.
AnoLLM: Large Language Models for Tabular Anomaly Detection
Ищем аномалии в табличных данных.
— Составляем из данных корпус текстов вида «фича Х равна Y, ...».
— Файнтюним.
— Оцениваем вероятность встретить значение фичи при условии значений других фичей, считаем NLL.
Достаточно маленьких моделей (130М — 1,7B).
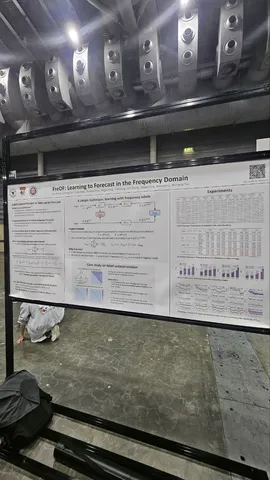
FreDF: Learning to Forecast in Frequency Domain
Для прогноза временных рядов авторы предлагают дополнительно к предсказанной и GT-последовательностям применять FFT и считать ещё один лосс между ними. Говорят, что получается неплохо.
А на последнем изображении тот самый экстравагантный стенд. Выглядит душевно!
Постеры заметили
#YaICLR
ML Underhood