Тренд на семантические ID развивается уже более полугода. Начало положила статья TIGER, в которой для генеративного ретривала контентные эмбеддинги айтемов квантовали с помощью RQ-VAE. Статья вышла ещё в 2023 году, но популярность к подходу начала приходить только после конференции RecSys в 2024-м.
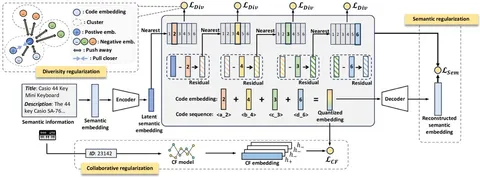
В сегодняшней статье авторы предлагают модификацию алгоритма квантизации — Learnable Item Tokenization for Generative Recommendation (LETTER). Новый подход основан на трёх идеях:
1. сохранение иерархичности семантической квантизации;
2. контрастивное сближение квантизаций и коллаборативных эмбеддингов (полученных через предобученный SASRec или LightGCN);
3. сглаживание распределений айтемов по центроидам кодбуков.
Еще одно отличие от TIGER — для того чтобы генерировать валидные коды, используются префиксные деревья по аналогии со статьей How to Index Item IDs for Recommendation Foundation Models.
Отдельное спасибо авторам хочется выразить за подробный ablation study числа кодов в иерархии квантизации: они отмечают, что увеличение числа кодов не всегда улучшает работу модели из-за накопления ошибки при авторегрессивном инференсе без teacher forcing. Очень полезны и данные о числах эмбеддингов в кодбуках.
Несмотря на большой вклад статьи в развитие семантической квантизации, у этой техники всё ещё остаются нерешенные проблемы. Для его реализации нужны:
1. предобученная контентная модель (в их случае это LLaMA-7B);
2. предобученная коллаборативная модель (например, SASRec или LightGCN);
3. другой подход к экспериментам — сейчас они, как правило, проводятся на открытых датасетах без time-split, из-за этого применимость метода в индустрии пока под вопросом.
@RecSysChannel
Разбор подготовил