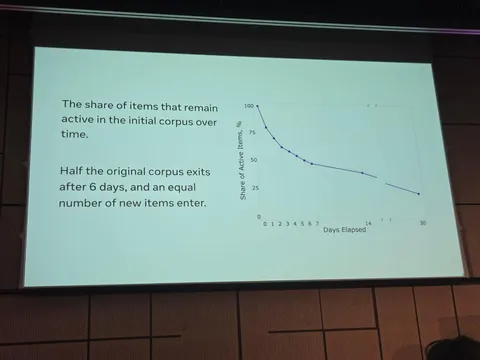
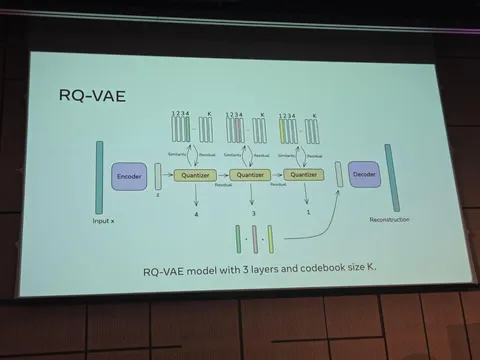
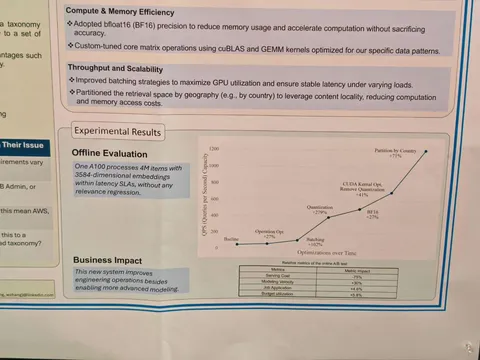
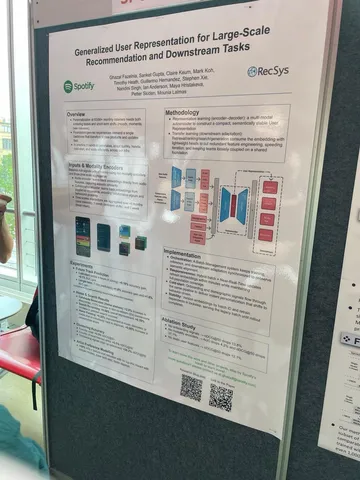
Какие статьи 2025 года перечитывают эксперты Рекомендательной. Часть 1
Прошедший год заметно изменил то, как мы представляли себе рекомендательные системы: границы между кандидатогенерацией, ранжированием и генеративностью начали стираться, а LLM всё чаще становятся частью рекомендательных алгоритмов. Мы собрали важные статьи, к которым эксперты Рекомендательной возвращаются снова и снова. Если вам есть что добавить или с чем поспорить — приходите обсуждать в комментарии!
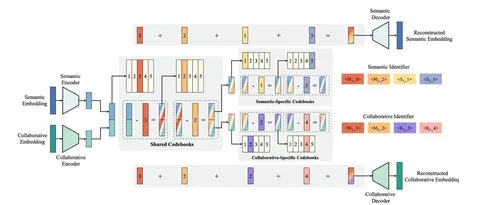
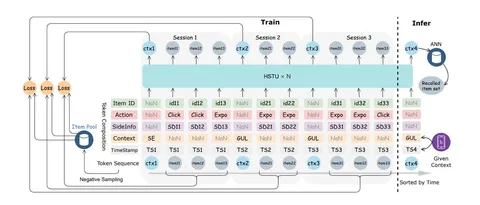
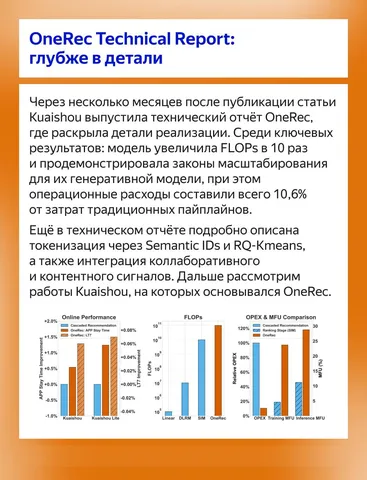
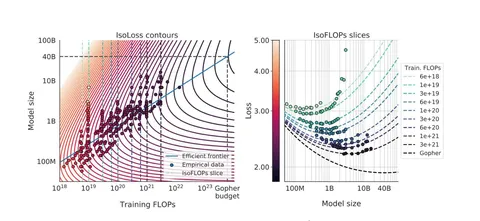
OneRec Technical Report и OneRec-V2 Technical Report
Самая хайповая серия статей этого года. Авторы первыми в мире объединили все стадии рекомендательной системы в единую генеративную нейросеть. Адаптировали техники, которые давно и активно применяются в других областях: претрейне, GRPO RL. Модель выкатили на 25% трафика одной из самых больших рекомендательных систем в мире с 400 млн DAU. В OneRec-V2 авторы уже реализуют описанные в первой части идеи ухода от схемы encoder-decoder и улучшения RL-обучения.
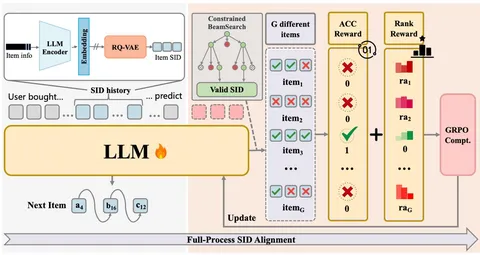
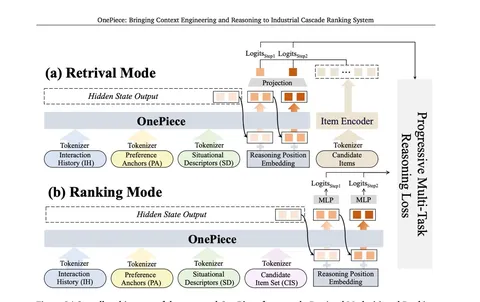
OneRec-Think: In-Text Reasoning for Generative Recommendation
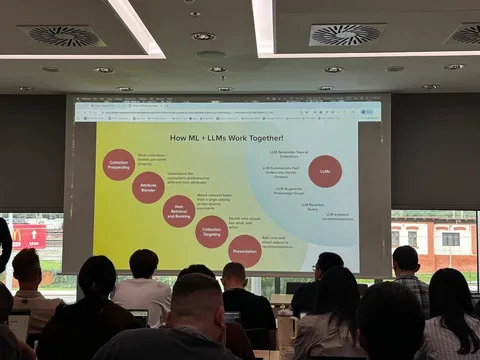
Исследователи одними из первых объединяют генеративные рекомендательные технологии и LLM. В статье показаны не только новые способности модели (текстовый интерфейс рекомендаций, ризонинг), но и внедрение в продакшн. Аналогичная работа от Deepmind вышла чуть раньше, но здесь авторы пошли дальше: добавили ризонинг и усложнили процедуру обучения.
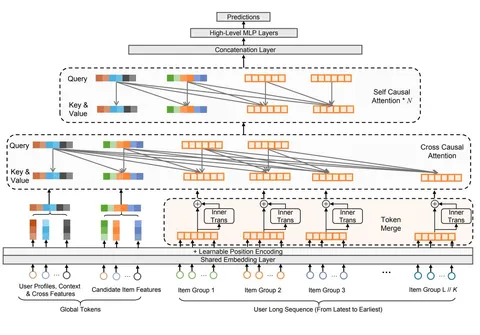
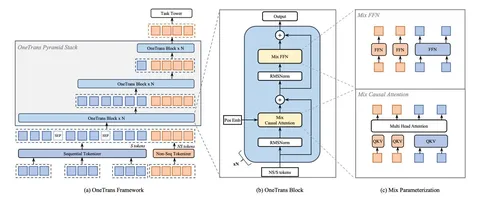
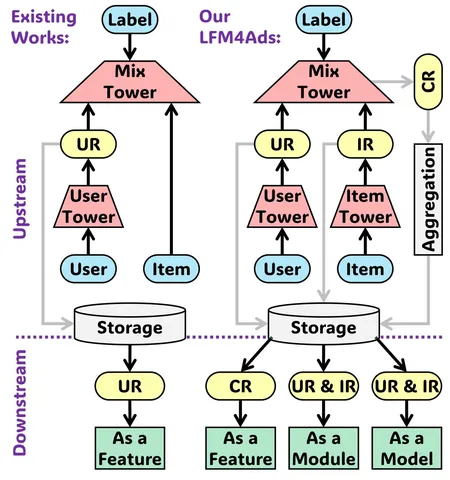
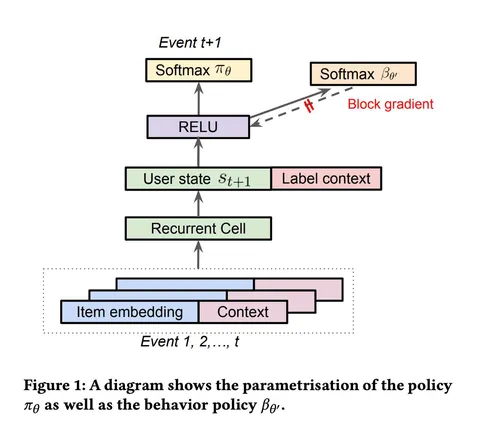
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Авторы построили фундаментальную модель, сочетающую различные органические и рекламные поверхности Meta*. Она объединяет ручное признаковое пространство и обработку сырых историй пользователей. Архитектура состоит из последовательных блоков трансформерных и interaction-слоёв. В статье — очень подробное описание и впечатляющие результаты внедрения.
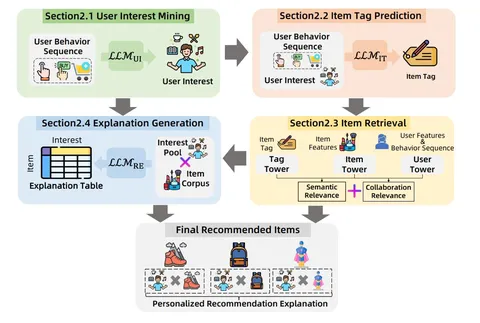
RecGPT Technical Report и RecGPT-V2 Technical Report
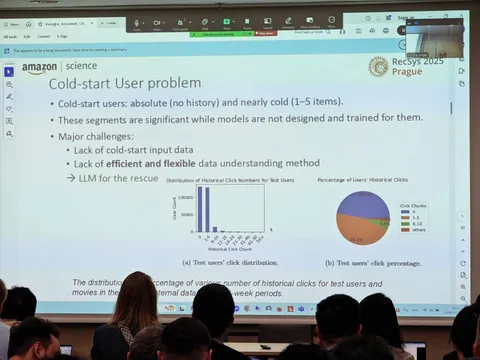
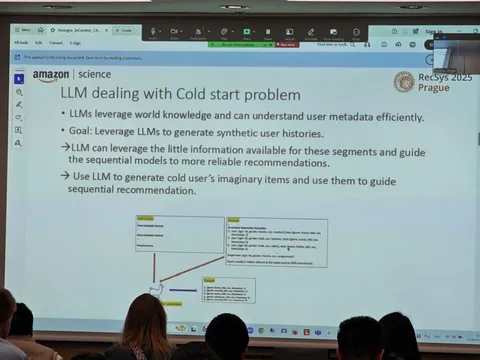
В техрепорте от Taobao рассказывается о создании их рекомендательной системы — на базе множества LLM. RecGPT позволяет хорошо учитывать не только коллаборативный сигнал, но и намерения, которыми руководствуются пользователи при выборе товаров, а также объяснять свои рекомендации на основе контекста и пользовательской истории. Подход получил развитие в техрепорте RecGPT-V2.
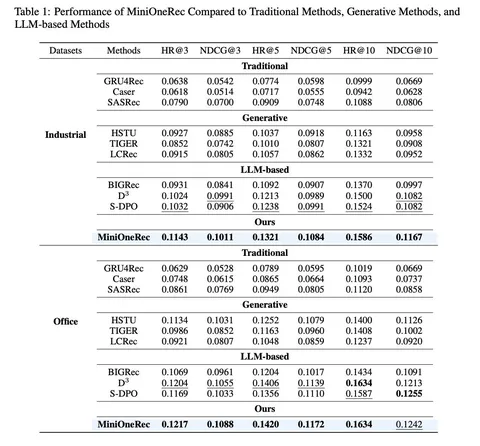
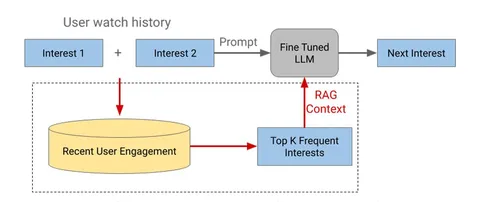
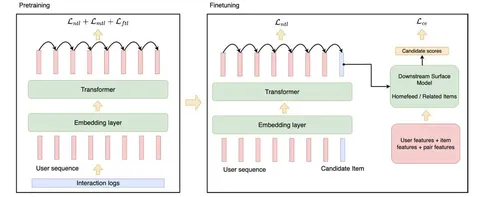
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
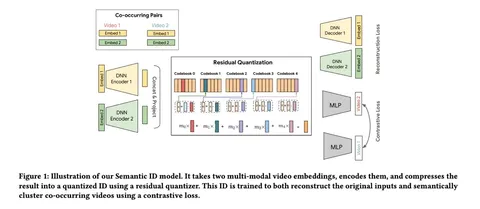
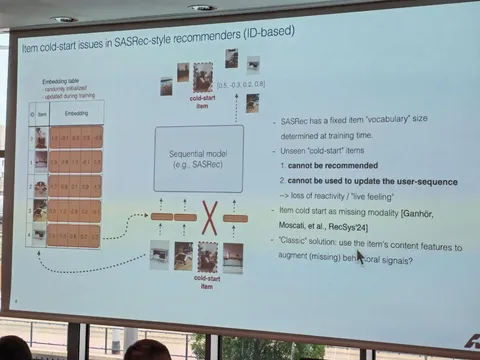
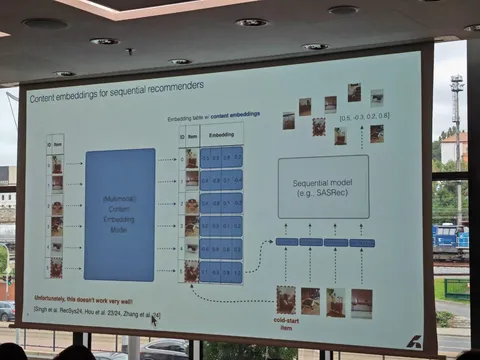
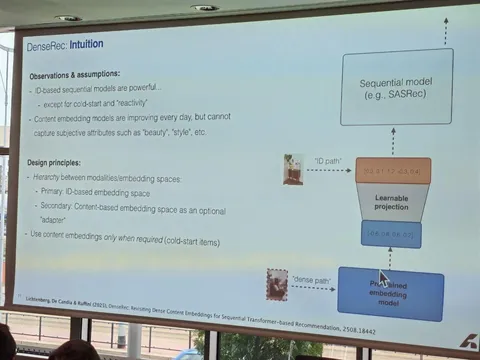
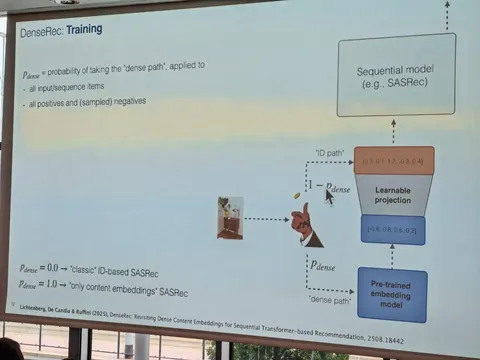
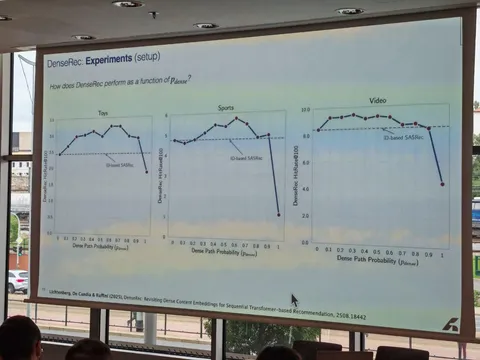
В этой работе авторы из Youtube и Google DeepMind рассматривают возможность переиспользовать предобученные LLM для задачи генеративного ретривала. Предложили два ключевых улучшения: инициализацию трансформера предобученной текстовой моделью, а также продолженный претрейн с использованием доменных данных (метаданных видео и пользовательских историй просмотров). В результатах показывают, что оба изменения независимо улучшают модель по метрикам генерации кандидатов. Статья выделяется тем, что в ней соединяется много современных трендов: RecSys+LLM, SemanticID и генеративная постановка задачи рекомендаций.
@RecSysChannel
Лучшие статьи отобрали❣ Николай Савушкин, Виктор Януш, Маргарита Мишустина
___
Meta признана экстремистской организацией, а Facebook и Instagram запрещены на территории РФ
Прошедший год заметно изменил то, как мы представляли себе рекомендательные системы: границы между кандидатогенерацией, ранжированием и генеративностью начали стираться, а LLM всё чаще становятся частью рекомендательных алгоритмов. Мы собрали важные статьи, к которым эксперты Рекомендательной возвращаются снова и снова. Если вам есть что добавить или с чем поспорить — приходите обсуждать в комментарии!
OneRec Technical Report и OneRec-V2 Technical Report
Самая хайповая серия статей этого года. Авторы первыми в мире объединили все стадии рекомендательной системы в единую генеративную нейросеть. Адаптировали техники, которые давно и активно применяются в других областях: претрейне, GRPO RL. Модель выкатили на 25% трафика одной из самых больших рекомендательных систем в мире с 400 млн DAU. В OneRec-V2 авторы уже реализуют описанные в первой части идеи ухода от схемы encoder-decoder и улучшения RL-обучения.
OneRec-Think: In-Text Reasoning for Generative Recommendation
Исследователи одними из первых объединяют генеративные рекомендательные технологии и LLM. В статье показаны не только новые способности модели (текстовый интерфейс рекомендаций, ризонинг), но и внедрение в продакшн. Аналогичная работа от Deepmind вышла чуть раньше, но здесь авторы пошли дальше: добавили ризонинг и усложнили процедуру обучения.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Авторы построили фундаментальную модель, сочетающую различные органические и рекламные поверхности Meta*. Она объединяет ручное признаковое пространство и обработку сырых историй пользователей. Архитектура состоит из последовательных блоков трансформерных и interaction-слоёв. В статье — очень подробное описание и впечатляющие результаты внедрения.
RecGPT Technical Report и RecGPT-V2 Technical Report
В техрепорте от Taobao рассказывается о создании их рекомендательной системы — на базе множества LLM. RecGPT позволяет хорошо учитывать не только коллаборативный сигнал, но и намерения, которыми руководствуются пользователи при выборе товаров, а также объяснять свои рекомендации на основе контекста и пользовательской истории. Подход получил развитие в техрепорте RecGPT-V2.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
В этой работе авторы из Youtube и Google DeepMind рассматривают возможность переиспользовать предобученные LLM для задачи генеративного ретривала. Предложили два ключевых улучшения: инициализацию трансформера предобученной текстовой моделью, а также продолженный претрейн с использованием доменных данных (метаданных видео и пользовательских историй просмотров). В результатах показывают, что оба изменения независимо улучшают модель по метрикам генерации кандидатов. Статья выделяется тем, что в ней соединяется много современных трендов: RecSys+LLM, SemanticID и генеративная постановка задачи рекомендаций.
@RecSysChannel
Лучшие статьи отобрали
___
Meta признана экстремистской организацией, а Facebook и Instagram запрещены на территории РФ
1 872 просмотров · 23 реакций
Открыть в Telegram · Открыть пост на сайте