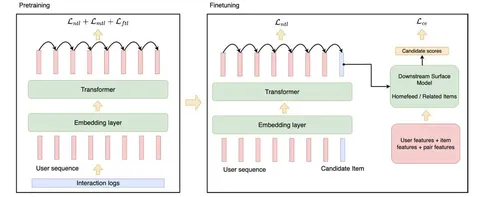
Продолжаем разбирать статью от Pinterest. Авторы не делятся внутренними параметрами модели, не уточняют, какого размера декодер и как всё обучалось. Однако они приводят масштабы всей системы — 20 миллиардов параметров. Судя по всему, большая часть этих параметров — матрица эмбеддингов. То есть модель в итоге получилась небольшой.
Отмечают, что в качестве энкодера выбрали архитектуру GPT2 и не увидели улучшений от применения HSTU-энкодера. Обучающую последовательность сформировали из 16 тысяч пользовательских взаимодействий, нарезав их на подпоследовательности длиной несколько сотен событий. Каждое событие кодируют обучаемыми эмбеддингами пина, поверхности и типа взаимодействия, итоговый токен события — сумма этих трёх эмбеддингов. Напоминает то, как формируются токены в Argus: де-факто есть те же context, item и action, но в весьма ограниченном варианте.
В остальном архитектура вышла стандартной. Но вот решаемую задачу авторы определяют весьма интересно. В качестве таргетов берут только позитивные события (при этом последовательность формируется с включением негативов), делают это с помощью Sampled Softmax (почему-то без LogQ-коррекции). В этом сетапе на стадии претрейна предсказывают:
– следующий позитивный токен;
– следующие позитивные токены в некотором временном окне;
– позитивные события, но во временном окне downstream-ранжирующей модели.
Получившийся лосс суммируют.
На файнтюне используют ещё несколько интересных трюков: выравнивают предсказания файнтюна и ранжирующей модели, добавляют дополнительный сигнал (контентно-коллаборативные графовые эмбеддинги) и обучаемые токены перед кандидатами, а также техники для решения проблемы холодного старта.
Команда Pinterest в очередной раз демонстрирует крутые инфраструктурные решения для жизнеспособность всей системы. В частности, эффективная дедупликация последовательности увеличила на 600% пропускную способность модели по сравнению с FlashAttention-2. Для оптимизации гигантской таблицы эмбеддингов применили агрессивную int4-квантизацию практически без потери качества.
В результате получилась сильная модель, хорошо агрегирующая знание о пользователях. Это отражается в результатах A/B-тестирования: на рекомендательной ленте на главной удалось добиться роста числа сохранений пинов на 2,6%, а для свежих пинов — на 5,7%.
@RecSysChannel
Разбор подготовил