Вчера в Праге стартовала конференция RecSys 2025. Первый день был посвящён в основном воркшопам. В промежутках можно было посмотреть постеры и пообщаться с авторами. Именно этим занимались инженеры Яндекса, которые уже разобрали несколько интересных работ.
In-Context Learning for Addressing User Cold-Start in Sequential Movie Recommenders
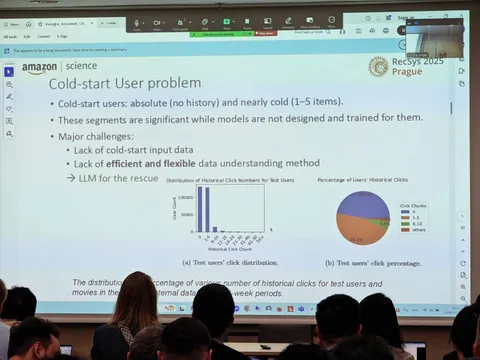
Авторы из Amazon используют sequential models (модели, основанные на цепочке событий пользователя) для задачи рекомендации видео, так как такие модели дают лучшее качество. В своих подходах указывают Recformer, SASRec, GRU4Rec, Tiger, Liger. Однако подобные модели чувствительны к проблеме холодного старта. Когда у пользователя ещё нет никакой истории, что ему показать? По данным авторов, таких пользователей — большинство: 47%, а еще 46% — имеют длину истории до пяти событий.
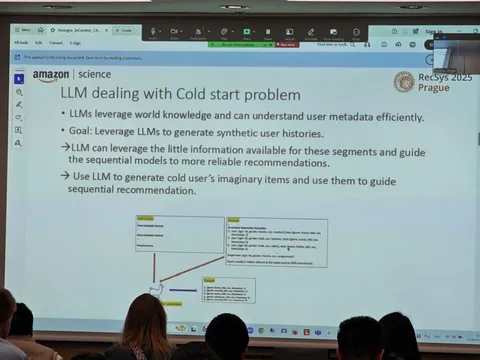
В качестве решения исследователи предлагают добавить к реальной истории пользователя выдуманную LLM (imaginary interactions). Её получают с помощью специально подготовленного промпта. Причём утверждают, что не так страшно, если модель сгаллюцинирует и вернёт несуществующие фильмы, так как это не финальная последовательность. Затем происходит объединение выдуманной истории с реальной. В работе используют два подхода:
— early fusion — просто объединяют выдуманную историю с реальной (последняя — реальная), формируя одну длинную последовательность;
— late fusion — генерируют k последовательностей независимо, каждую продолжают реальной, а потом делают avg pooling над эмбедами.
В экспериментах авторы репортят два датасета: публичный the MovieLens 1M и проприетарный the Amazon Proprietary. Early fusion лучше себя показал на публичном датасете, причём бустит он именно «холодных» пользователей, тогда как на более «горячих» его влияние пропадает. А вот на проприетарном датасете лучше сработала late fusion. Это объясняют тем, что подход добавляет разнообразия выдаче.
Следующие шаги:
— из k произвольных фильмов заданного жанра предложить LLM выбрать подходящий;
— добавить RAG;
— собирать информацию для «холодных» пользователей путём опроса.
DenseRec: Revisiting Dense Content Embeddings for Sequential Transformer-based Recommendation
Основные идеи:
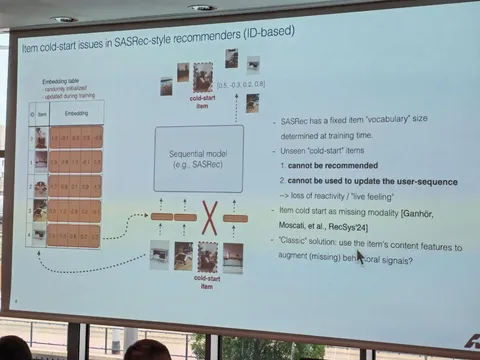
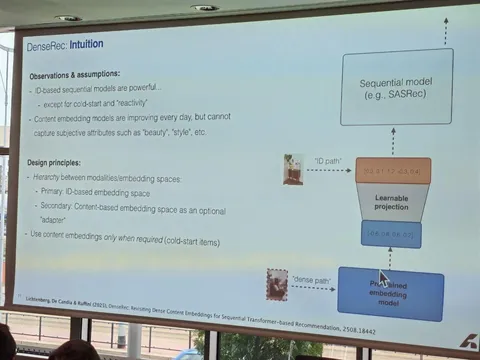
— SASRec хорошо работает, но плохо справляется с cold items. Надо поправить эту проблему (другие подходы, например, semantic IDs требуют сильного изменения всего пайплайна).
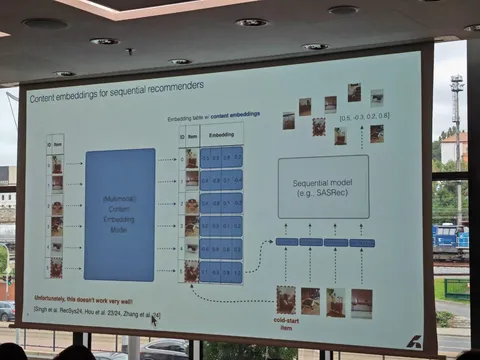
— Предлагается использовать контентные фичи. Но замена «в лоб» просаживает качество.
— Предлагается выучить модель, которая будет работать поверх всё той же embedding table по ID в части случаев, но также научиться переводить в это пространство контентные фичи.
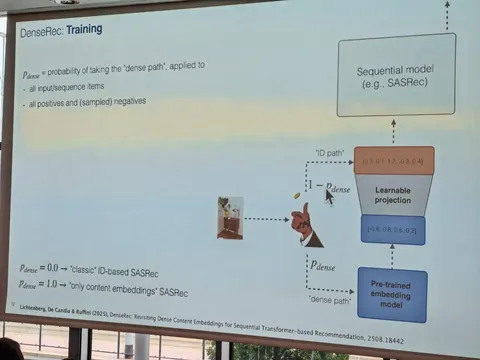
— Формально при обучении подбрасывают монетку для каждой позиции в последовательности айтемов, с вероятностью p берут эмбед из таблицы эмбеддингов, с вероятностью (1-p) берут конктентные фичи и с помощью простой модели (в данном случае — линейной проекции) переводят контентные эмбеды в пространство обычных.
— При инференсе для знакомых ID всегда используют таблицу эмбедов, для новых — конкретные фичи и линейный слой проекции.
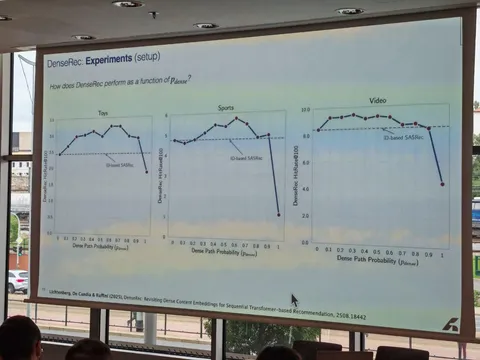
— В экспериментах на датасете Amazon авторы показывают значимое улучшение метрик, причём основной прирост — не на «холодных» документах. Авторы объясняют это тем, что подход обучения с использованием контентных фичей не только улучшает их представление (new items as target), но и улучшает качество самой последовательности (new items in the sequence).
@RecSysChannel
Статьи заметил