Разбираем статью от Pinterest, в которой говорят об использовании максимально длинной истории действий для улучшения рекомендаций в ленте. Задача осложняется жёсткими инфраструктурными ограничениями: Pinterest обслуживает более 500 млн пользователей в месяц, а объём возможных кандидатов — миллиарды пинов. При этом инференс должен укладываться в строгие тайминги, несмотря на тысячи параллельных GPU-запросов.
Pinterest остаётся верен классической трёхстадийной архитектуре: retrieval — scoring — blending. На первом этапе модель отбирает несколько тысяч кандидатов, которые затем проходят pointwise-ранжирование. Ранжирующая модель оптимизируется исключительно под фид. Особое внимание уделяется тому, как используется длинная история действий — ключевое отличие от предыдущих решений.
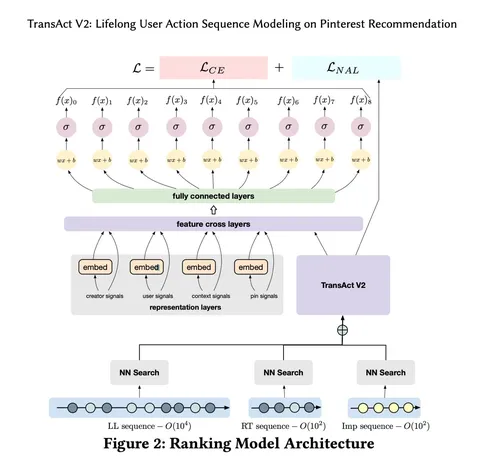
Несмотря на эффектный посыл про «десятки тысяч событий в истории», фактически модель работает не с «сырой» историей, а с её сжатием. История формируется из трёх источников: полной пользовательской активности, событий в рантайме и импрессий. Для каждого кандидата модель отбирает ближайшие по контенту события из этих источников (а также несколько последних взаимодействий независимо от контента), формируя итоговую последовательность фиксированной длины — порядка сотен событий. Эта сжатая история и обрабатывается в трансформере.
Модель представляет собой multitask-архитектуру в pointwise-постановке. На вход она получает эмбеддинги, включающие обучаемые параметры, категорию взаимодействия, позиционный эмбеддинг и эмбеддинг пина. Последний строится как объединение эмбеддинга кандидата и карточек из истории, к которым кандидат наиболее близок по контенту. Трансформер с минимальным числом параметров (два слоя, одна attention-глава, скрытое представление размерности 64) пропускает эту последовательность и генерирует выходные векторы, которые подаются в линейный слой для генерации прогнозов.
Loss-модель использует два компонента: взвешенную кросс-энтропию по каждому действию (лайк, добавление в избранное и прочее) и sampled softmax loss на задачу next action prediction. В качестве позитивов используются все позитивные взаимодействия в последовательности, а в качестве негативов — показы. Авторы отмечают, что подход показывает себя лучше, чем batch sampling. Среди архитектурных решений также интересно, что один и тот же пин, встретившийся с разными действиями, кодируется как multi-hot-вектор, а эмбеддинги пинов хранятся в квантизованном виде (int8) и деквантизируются в float16 перед подачей в трансформер.
Ключевые нововведения — в инфраструктуре. Стандартные решения на PyTorch оказались неприменимы из-за избыточной материализации данных. Разработчики переписали инференс на собственный сервер с кастомными трансформерными ядрами в Triton (речь не о сервере NVIDIA, а о языке для компиляции под GPU). Такой подход позволил избежать дополнительных обращений к памяти: квантизованные векторы декодируются, нормализуются и сразу же используются для поиска ближайших соседей.
Ещё в работе реализовали оптимизации вроде кэширования длинных пользовательских историй в сессии (чтобы избежать их загрузки при каждом реквесте), дедупликации запросов и эффективного распределения памяти между CPU и GPU. Всё вместе это дало серьезный прирост производительности: latency снизился в 2–3 раза по сравнению с PyTorch, использование памяти тоже оказалось эффективным. Переход на собственные ядра позволил сократить время инференса на 85% и расход памяти на 13% при длине последовательности 192. Решение выигрывает и у FlashAttention 2: ядра оказались на 66% быстрее и потребляли на 5% меньше памяти, при этом FlashAttention 2 не поддерживает пользовательское маскирование токенов.
Авторы сравнивают эффективность TransAct V2 с другими моделями, в том числе с первым TransAct. Основной вывод: использование гораздо более длинной пользовательской истории и набор инженерных решений дают заметный прирост качества рекомендаций без потерь в скорости и стабильности.
@RecSysChannel
Разбор подготовил