Тема масштабирования моделей в рекомендательных системах продолжает набирать популярность. Недавно Alibaba представила работу о масштабировании ранжирующих моделей для персональных рекомендаций товаров на AliExpress. О ней и поговорим.
В ML выделяют два класса вероятностных моделей:
— Дискриминативные — моделируют условное распределение p(y|x) (предсказывают метку y по данным x). Примеры: логистическая регрессия, большинство моделей для ранжирования.
— Генеративные — моделируют совместное распределение p(x, y), что позволяет генерировать данные. Примеры: GPT, диффузионные модели.
Авторы фокусируются на дискриминативных ранжирующих моделях, предсказывающих CTR и CVR. Однако при попытке масштабировать трансформер, обучаемый только на дискриминативную задачу, наблюдается переобучение. Это связано с сильной разреженностью позитивного таргета для ранжирования: увеличение модели ведёт к деградации качества.
Решение — добавить генеративное предобучание (метод назван GPSD — Generative Pretraining for Scalable Discriminative Recommendation), а затем — дискриминативное дообучение. Ключевое преимущество заключается в том, что генеративное предобучание не страдает от сильного разрыва в обобщающей способности между обучением и валидацией, что и открывает путь к масштабированию.
Технические детали
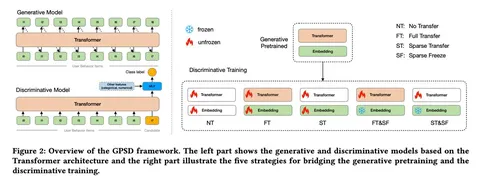
1. Генеративное предобучение
— Используется архитектура трансформера с каузальной маской над историей взаимодействий.
— Модель решает две задачи: предсказание следующего товара (Sampled Softmax Loss с равномерно семплированными негативами из каталога) и предсказание его категории.
— При кодировании товаров применяются обучаемые эмбеддинги для каждого айтема, а также дополнительные фичи, такие как категория.
— Агрегация делается путём суммирования.
2. Дискриминативное дообучение
— Добавляется CLS-токен в историю. Его выходной вектор используется как представление пользователя.
— Это представление конкатенируется с фичами кандидата (товара, для которого предсказывается CTR) и подается на вход MLP.
3. Стратегия переноса весов
— Наилучшие результаты даёт инициализация и заморозка матриц эмбеддингов (item embeddings) с этапа генеративного предобучения.
— Веса самого трансформера можно инициализировать как предобученными, так и случайными значениями — результат сопоставим.
Ключевые результаты
— Без генеративного предобучения: увеличение модели не даёт прироста качества (AUC) из-за переобучения, наблюдается даже деградация.
— С GPSD: устойчивое масштабирование — рост AUC при увеличении размера модели от 13 тысяч до 300 млн параметров. Выведен степенной закон зависимости AUC от числа параметров.
— A/B-тест на рекомендательной платформе AliExpress: в продакшен выведена модель с тремя слоями трансформера и скрытой размерностью 160 (очень компактная).
Результат: +7,97% GMV, +1,79% покупок.
Замечания
1. Использованные модели и датасеты — небольшие, что немного подрывает веру в результаты.
2. При масштабировании одновременно с dense-частью (трансформер) увеличивались и sparse-часть (матрицы эмбеддингов), что также могло быть фактором роста качества. Для более честного замера её размер нужно было зафиксировать.
@RecSysChannel
Разбор подготовил