Разбираем одну из самых интересных статей на тему рекомендательных систем с ICLR 2025. Её авторы задаются вопросом: действительно ли LLM неявно кодируют информацию о предпочтениях пользователей. В работе предлагается использовать эмбеддинги айтемов из LLM для улучшения качества рекомендаций.
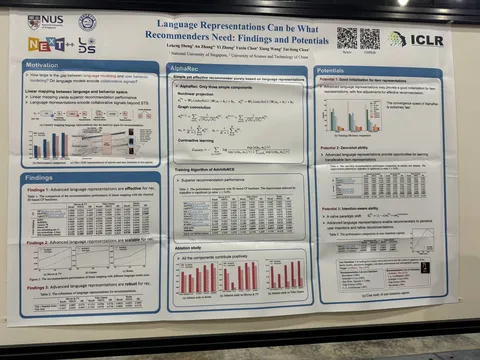
В начале статьи упоминается, что LLM хорошо показывают себя во многих доменах, а также приводится обзор вариантов их применения к ранжированию в рекомендательных системах. Один из таких вариантов — использовать замороженную языковую модель для получения эмбеддинга текста/названия айтема, а затем — дообучать линейный слой для подсчёта итогового представления айтема.
Таким образом можно извлечь и представление пользователя, усреднив эмбеддинги айтемов из его истории взаимодействий. Представления пользователей и айтемов затем используются для получения скора ранжирования (например, с помощью dot-product).
Этот подход немного улучшает качество существующих методов, и авторы задумываются о причинах этого улучшения. Они отмечают, что фильмы на разные темы близки в пространстве языковых эмбеддов (например, запросы пользователей) и в пространстве непосредственно айтемов (например, названия фильмов). Внимание акцентируют на линейном отображении, которое позволяет кластеризовать эмбеддинги айтемов, отображая схожесть пользователей, которые ими интересуются.
В статье рассуждают о нескольких вариантах кодирования айтемов: с использованием ID и матриц эмбеддов, с использованием LLM. У первого подхода есть недостатки: например, плохая переносимость эмбеддингов между доменами и отсутствие явной возможности распознавать намерения пользователей. Их и призван нивелировать второй подход.
Главные вопросы, на которые хотят ответить в статье: кодируют ли LLM коллаборативный сигнал и насколько наличие сигнала зависит от размеров модели. Сравниваясь с существующими методами на модельных датасетах, авторы приходят к выводам о превосходстве представлений, полученных с помощью LLM, над ID-based подходом. Также утверждают, что с увеличением размера модели увеличивается репрезентативность пользовательских интересов.
Ключевая идея — итеративное построение эмбеддингов пользователей и айтемов по графу взаимодействий с использованием нелинейностей и представлений LLM — в статье этот метод называется AlphaRec. Для обучения моделей авторы предлагают использовать случайно сэмплированные негативы из числа тех айтемов, с которыми пользователи не взаимодействовали. На рассмотренных датасетах AlphaRec обходит существующие алгоритмы как по качеству, так и по необходимым вычислительным мощностям. Ещё одно преимущество этого фреймворка — возможность предоставить готовые эмбеддинги для инициализации другими алгоритмами ранжирования.
В конце статьи авторы рассматривают применение пользовательского интента (например, запрос с описанием фильма, который пользователь хотел бы потенциально посмотреть) для улучшения качества рекомендаций. Использование AlphaRec в этом случае позволяет получить результаты, кратно превосходящие другие методы. Однако датасет для такого исследования был сгенерирован синтетически с помощью асессоров и не защищен от ликов — то есть, скорее всего, он не означает, что в случае использования чат-бота или поискового запроса предложенный алгоритм будет настолько же хорош.
@RecSysChannel
Обзор подготовила
#YaICLR