Авторы рассказывают, как строили систему ранжирования: комбинировали известные архитектуры и оптимизировали их, чтобы сократить время обучения и улучшить метрики. Результат: +0,5% сессий пользователей в ленте, +1,76% квалифицированных заявок на работу, +4,3% CTR объявлений.
Предлагают:
— 2 версии MTL для предсказания engagement и CTR;
— Residual DCN с attention-схемой;
— изотонический калибровочный слой, который учится вместе с моделью;
…и другое. В двух словах расскажем здесь, а подробности ищите в статье.
Ранжирование
Point-wise подход используют для оценки вероятности лайков, комментариев и репостов в паре пост — юзер. С помощью TF-модели с MTL-архитектурой вероятности комбинируют, группируя задачи в тасках.
Предсказание CTR
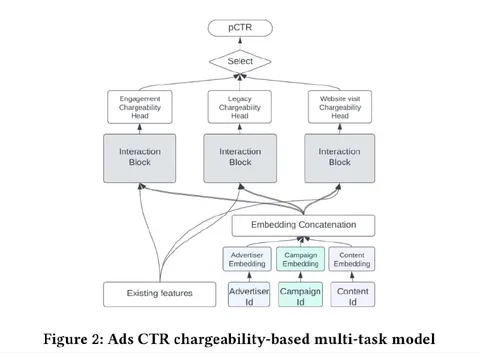
В модели с 3 башнями по-разному группируют взаимодействия, ориентируясь на цели рекламодателей: кто-то считает прибыльными лайки и комментарии, а кто-то — только клики. В каждой из голов используются свои interaction-блоки (MLP, DCNv2), loss тоже отбирают в зависимости от задачи.
Residual DCN — расширение DCNv2
Матрицу весов заменяют 2 тонкими матрицами — это похоже на low-rank аппроксимацию — и уменьшают размерность входных фич. Число параметров сокращается почти без потери качества, а модель запускается на CPU. В неё добавляют attention-схему, где исходное low-rank отображение дублируется в виде 3 матриц: Query, Key и Value. Их перемножают и добавляют residual connection от Value, умноженной на исходный вектор. Параллельно используется стандартный low-rank DCN. Когда тюнят температуру, получается ещё лучше.
Калибровочный слой
Обучается с моделью, работает примерно как изотоническая регрессия. Однако здесь кусочно-линейную функцию вычисляют, разбивая на блоки вещественную прямую. Неотрицательные веса гарантируют с помощью Relu-функции, дополнительных весов и калибровочных фичей. Результат используют как последний слой.
И это не всё… Расскажем о других оптимизациях в продолжении 😃
@RecSysChannel
Разбор подготовил