Финал обзора статьи от LinkedIn об оптимизациях в рекомендательных системах. Поехали!
Wide Popularity Features
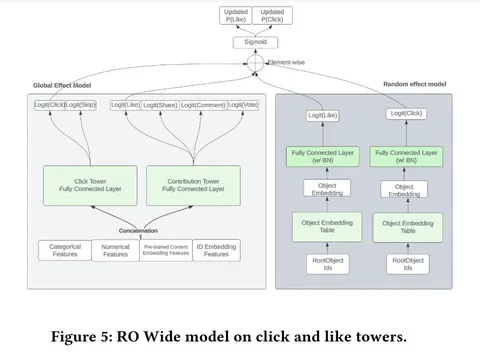
Random effect модель нужна, чтобы к обычной модели с миллиардами параметров добавить связи, указывающие на происходящее в данный момент. Модель дообучается раз в 8 часов и выдаёт самую актуальную информацию: айтемы с высокой волатильностью, коротким сроком жизни и т. д. Итоговый предикт — это сигмоида от суммы логитов двух моделей — основной и random effect.
Dwell Time Modeling
Просто брать время на просмотр поста (dwell time) и использовать его при расчёте вероятностей оказалось неэффективно: данные шумные, а статические пороги не адаптируются под предпочтения пользователя и смещают оценку.
Решение — бинарный классификатор, который предсказывает, будет ли юзер сидеть на посте больше, чем, к примеру, 90% пользователей. Оценка даётся на основе позиции в ленте, типа контента, платформы и т. д. Айтемы кластеризуют и проводят отбор внутри. Авторы утверждают, что при ежедневном обновлении получается +0,2% сессий и +1% dwell time.
Model Dictionary Compression
Экономить память помогает QR-хешинг — большие матрицы с категориальными sparse-фичами высокого разрешения декомпозируют в маленькие. 4 миллиарда строк сжимают в 1000 раз, ещё около 1000 получают из «остатков». Remainder-матрица позволяет сохранить уникальность эмбеддингов в разрезе ID и повысить их репрезентативность.
Embedding Table Quantization
Post-training квантизацию делают не по min—max, а по middle—max. Есть две причины:
— эмбеддинги имеют нормальное распределение, поэтому больше всего значений в центре;
— диапазон значений эмбеддингов — от -128 до 127, что решает проблему дополнительного кода.
Это была эпическая серия! Если вам мало оптимизаций от LinkedIn, в оригинальной статье есть ещё часть про масштабирование обучения и эксперименты — читайте и делитесь впечатлениями :) А нам пора двигаться дальше.
@RecSysChannel
Разбор подготовил