Обучение на логах юзеров может приводить к popularity bias. Мы рекомендуем айтемы, человек их смотрит, это попадает в логи и оттуда — в дальнейшее обучение. В итоге «богатый становится богаче». Известные способы борьбы с этим ухудшают перфоманс популярных айтемов, что тоже плохо. Ресёрчеры из DeepMind предлагают свой метод, Cluster Anchor Regularization, и применяют его для YouTube Shorts.
Иерархическая кластеризация
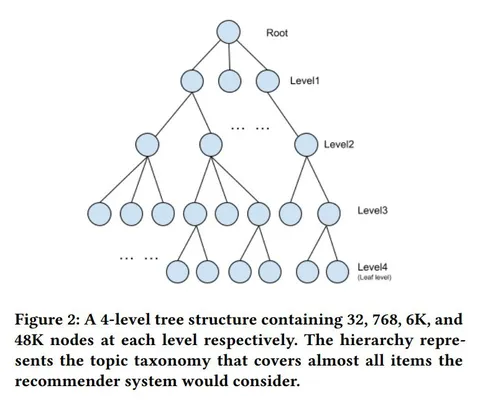
Индекс делится на кластеры, затем каждый из них кластеризуют снова — так мы получаем следующие уровни. Для каждого кластера учим эмбеддинг, чтобы приблизить к нему tail-айтемы того же кластера.
Кластеры генерируют энкодером с учётом метаданных и контента. 2-миллиардный индекс мапится в 256-размерные эмбеддинги. Они фиксированы, считаются один раз и нужны лишь для построения графа, который и будет кластеризоваться. Об архитектуре энкодера авторы не пишут.
Ноды графа — айтемы, а рёбра отражают косинусную близость между ними. Граф разбивается на кластеры так, что рёбра, выходящие из одного кластера и приходящие в другой, получают меньший вес. Каждой ноде сопоставляют вес, равный √ числа взаимодействий с айтемом. После 4 уровней кластеризации получается 48 000 кластеров. В каждом из них внутри одного уровня примерно одинаковое число взаимодействий.
Якорная регуляризация
Внутри кластеров есть source- и target-айтемы. В нашем случае source — популярные айтемы, а target — непопулярные. Каждому айтему сопоставляем его обучаемый эмбеддинг, а каждому кластеру — эмбеддинг такой же размерности. На первом этапе source-айтемы мапятся в свои кластеры, а представления кластеров обучают так, что градиент просачивается в них, не изменяя source-векторы.
На втором этапе то же самое происходит с target-айтемами, но обновляется уже не представление кластера, а векторы target’ов. Результаты обоих этапов добавляем в основной loss. Благодаря этому получается «эффект якоря»: популярные айтемы «тянут» за собой непопулярные.
@RecSysChannel
Разбор подготовил