Сегодня разбираем статью от Pinterest о модели PinRec. В индустрии существуют два основных подхода к transformer-based retrieval. Первый — классическая двухбашенная схема: трансформер анализирует пользовательскую историю и сжимает её в эмбеддинг, с которым затем обращаемся к HNSW-индексу, построенному на айтемных эмбеддингах. Второй подход — появившиеся относительно недавно генеративные модели, в которых трансформер порождает непосредственно список айтемов, релевантных для данного юзера, например генерируя их в виде последовательностей семантических айдишников.
В модели PinRec авторы совмещают обе парадигмы и получают нечто среднее: с одной стороны, трансформер генерирует последовательность, однако это последовательность не айтемных идентификаторов, а сырых эмбеддингов, с каждым из которых затем ходим в HNSW-индекс для поиска ближайших айтемных эмбеддингов.
В базовой версии модель представляет собой трансформер с каузальной маской, авторегрессивно предсказывающий каждый следующий айтем, с которым провзаимодействовал пользователь, при условии его предыдущей истории. Учится модель на sampled softmax loss с logQ-коррекцией и mixed-negative sampling (используются in-batch и random-негативы). На инференсе предсказываем по истории пользователя эмбеддинг следующего айтема, дописываем его в сыром виде в конец истории и повторяем такой процесс несколько раз — в результате генерируем последовательность эмбеддингов и от каждого из них набираем ближайшие айтемы в HNSW-индексе.
Помимо указанного совмещения парадигм ключевые новшества статьи — это две идеи, навешиваемые поверх базовой версии модели.
Во-первых, авторы предлагают способ, при помощи которого можно обуславливать генерацию на желаемые действия пользователя — не прибегая к SFT и RL. При предсказании следующего айтема будем давать модели информацию о действии, совершенном юзером с этим айтемом. А именно, будем конкатить выход из трансформера, сжимающий предыдущую историю, с эмбеддингом действия и уже из этого конката предсказывать следующий айтем. Такая схема позволяет на инференсе подставить эмбеддинг нужного нам действия и предсказать наиболее вероятные айтемы при условии этого действия.
Во-вторых, авторы замечают, что взаимодействия пользователя с айтемами в сервисе совершенно не обязательно имеют строго последовательную логику и жёсткую очередность. А задача next item prediction как раз предполагает, что для каждой предыстории есть ровно один верный предикт — тот айтем, с которым пользователь провзаимодействовал следующим.
В статье предлагается изменить постановку задачи: важно угадать не в точности следующий айтем, а хотя бы один из будущих айтемов в некотором временном окне. Для этого вводится такая модификация лосса — обычный sampled softmax loss посчитаем по всем айтемам в этом окне и затем возьмём минимум из полученных значений. Тогда и на инференсе можно предсказывать не по одному эмбеддингу за раз, а сразу целыми окнами. В статье утверждается, что это повышает и качество, и разнообразие кандидатов, а за счёт генерации целыми окнами значительно ускоряет инференс.
Авторы репортят, что описываемая ими модель внедрена как один из кандидатогенераторов в Pinterest на весь их внушительный industrial scale. При этом получены значимые приросты онлайн-метрик: на поверхности homefeed +0,28% fulfilled sessions, +0,55% timespent и +3,33% кликов.
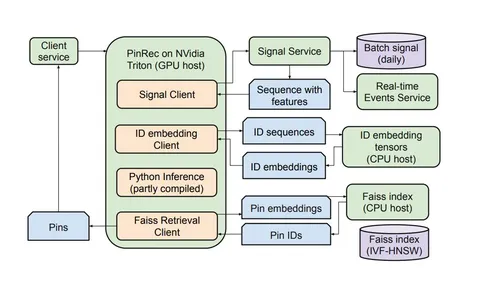
Помимо архитектурных идей статья содержит интересные детали сервинга модели в продакшене (используется Triton Inference Server с Python-бэкендом). Также авторы сравнивают в своём сетапе трансформер с архитектурой HSTU (не в пользу последней), проводят эксперименты со скейлингом трансформера вплоть до миллиарда параметров и репортят, что добавление в модель таблицы id-based-эмбеддингов с 10 миллиардами параметров докидывает +14% к recall@10 поверх только контентных эмбеддингов.
@RecSysChannel
Разбор подготовил