Делимся ещё несколькими работами, которые показались любопытными инженерам Яндекса. В сегодняшней подборке: диффузионки, которые генерируют целые плейлисты, борьба с cold start, обучение семантических ID на все задачи сразу и презентация с иллюстрациями из мультика «Холодное сердце».
Prompt-to-Slate: Diffusion Models for Prompt-Conditioned Slate Generation
Авторы представили DMSG — диффузионную модель для генерации целых наборов контента (плейлисты, корзины товаров) по текстовому запросу. Ключевая идея: вместо ранжирования отдельных элементов сеть учится порождать весь слейт целиком.
Каждый объект каталога кодируется вектором-эмбеддингом. Слейт фиксированной длины представляют как конкатенацию этих векторов. Текстовый промпт кодируется трансформером и подаётся в Diffusion Transformer через cross-attention. Диффузионная часть пошагово «разшумляет» случайный вектор в латент слейта. Готовые латенты проецируются в ближайшие объекты каталога с фильтрацией дублей.
Такой подход даёт согласованность набора, стохастичность и разнообразие (несколько валидных слейтов для одного промпта). В экспериментах на музыкальных плейлистах и e-commerce-бандлах модель показала до +17% по NDCG и +6,8% взаимодействий в онлайне.
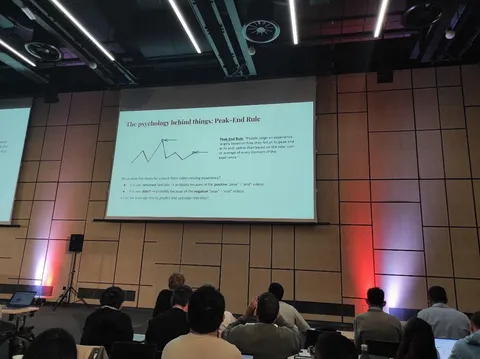
Not All Impressions Are Created Equal: Psychology-Informed Retention Optimization for Short-Form Video Recommendation
Хорошая идея для рексистем с плотным пользовательским сигналом. В таргет ставится ретеншн (вернётся ли пользователь в сервис завтра), а в текущей сессии выделяются пиковый и последний документы — психологически именно они запоминаются и влияют на решение вернуться. Для поиска пика используют как положительные, так и отрицательные взаимодействия в сессии.
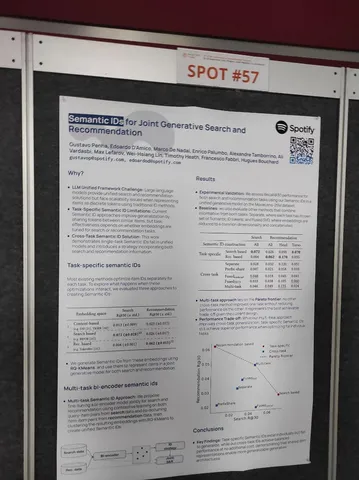
Semantic IDs for Joint Generative Search and Recommendation
Довольно простая, но, скорее всего, рабочая мысль — учить семантические ID документов сразу на все задачи. По сути то же, что и обучение многоголовых сетей, только применительно не к эмбедам, а к семантической токенизации документов.
Let it Go? Not Quite: Addressing Item Cold Start in Sequential Recommendations with Content-Based Initialization
Авторы сначала учат эмбеддинги документов только на контенте, а затем доучивают на ID, контролируя, чтобы норма изменения эмбеддинга оставалась малой. Говорят, это хорошо работает на «холодных» документах, и при этом на «горячих» качество почти не проседает. А ещё в презентации статьи были шикарные иллюстрации с героями из мультика «Холодное сердце».
@RecSysChannel
Статьи выбрали