Разбираем работу Alibaba, архитектурно напоминающую ARGUS, используемый в Рекламе Яндекса. Модель TBG Recall, описанная в статье, генерирует кандидатов для главной страницы Taobao, крупнейшего e-commerce-сервиса компании.
Во многих работах для рекомендаций применяются генеративные и последовательные модели, но они предполагают, что история пользователя — это строгая последовательность событий. В e-commerce всё иначе: пользователь делает запрос и получает «пачку» товаров, потом ещё одну — внутри таких пачек никакой упорядоченности нет, поэтому обычные sequence-based-подходы здесь работают не совсем корректно.
В качестве решения авторы вводят предсказание следующей сессии, где сессия понимается как один запрос пользователя. Модель учится предсказывать, какие товары пользователь увидит в следующей выдаче.Также в работе используют incremental training, чтобы регулярно обновлять модель на свежих данных без перерасхода GPU.
Архитектура
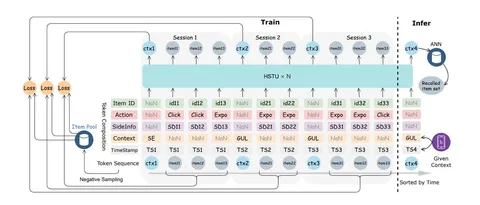
Как уже сказали, в основе TBGRecall — next session prediction: история пользователя кодируется в вектор и сравнивается с векторами кандидатов через ANN-индекс, как в классических двухбашенных моделях. Слово «генеративная» в названии относится не к инференсу, а к способу обучения — авторегрессионному.
В начале каждой сессии стоит контекстный токен — обобщённое описание запроса. При инференсе он формируется из текущего контекста пользователя и напрямую влияет на итоговый вектор, с которым рекомендательная система делает запрос в индекс. По нашим наблюдениям, контекстные токены дают почти двукратный прирост качества — особенно в сервисах вроде Поиска и Рекламы, где контекст крайне важен.
Кодирование и обучение
Каждое событие описывается набором признаков: Item ID, Action, SideInfo (ID продавца или категория), Context и Timestamp. Вход модели — сумма этих векторов. Сначала они проходят через tower-модули, а затем через HSTU-блоки. Для контекстных и айтемных токенов используются отдельные tower-модули — небольшие проекции, без которых качество падает (что совпадает с нашим опытом в ARGUS).
Основная схема обучения — session-wise autoregressive approach с маской внимания, которая не позволяет айтемам внутри одной сессии «видеть» друг друга. Также применяется session-wise ROPE (sw-ROPE) — позиционные эмбеддинги, нумерующие сессии. Мы пока не видели стабильного выигрыша от подобных схем, но идея любопытная.
Лосс состоит из трёх частей:
1. Lnce — воспроизводит логирующую политику, учит отличать реальные айтемы в сессии от случайных негативов.
2. Lclick — отличает кликнутые айтемы от показанных.
3. Lpay — отличает купленные от всех прочих.
Все три компоненты считаются по разным продуктовым сценариям и взвешиваются по числу сессий в них. Отдельного претрейна или fine-tune-фазы, как в ARGUS, нет — всё обучение проходит за один этап.
Инференс и результаты
В проде модель работает не в реальном времени: кандидаты пересчитываются асинхронно и обновляются с небольшой задержкой. Авторы считают, что контекст пользователя меняется нечасто, поэтому такая схема не вредит качеству.
На закрытом датасете (около 2 трлн записей) TBGRecall превзошёл собственный dual-tower baseline компании. В A/B-тестах модель показала +0,5% по числу транзакций и +2% по обороту. Новый кандидат-генератор теперь отвечает за 24% показов на поверхности Guess You Like — одной из ключевых страниц Taobao.
В целом, TBGRecall — это шаг от классической двухбашенной архитектуры к генеративному обучению. Контекстные токены дают сильный прирост, MoE и SW-ROPE работают стабильно, а near-line-инференс показывает себя лучше, чем ожидалось.
@RecSysChannel
Разбор подготовил