Сегодня разбираем совместную статью Google DeepMind и YouTube. Об этой работе было известно заранее — на конференции RecSys авторы проекта, включая Ed Chi и Lichan Hong, упоминали, что готовится статья о генеративных рекомендациях. Через пару недель после конференции она действительно вышла.
Исследование продолжает трек генеративных рекомендаций, заданный предыдущей работой авторов TIGER. На этот раз основная идея — использование предобученных больших языковых моделей в рекомендательных пайплайнах (в случае Google — это Gemini). Простая LLM из коробки не подходит: модель не знает ни о корпусе айтемов, ни о пользовательских поведенческих сценариях, что приводит к плохим результатам. Чтобы исправить это, команда предлагает фреймворк PLUM, включающий три стадии: item tokenization, continued pre-training и task-specific fine-tuning. Кратко разберём каждую из них.
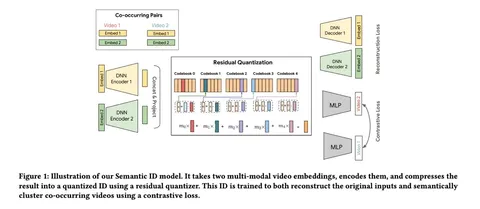
1) Item tokenization. За основу взята работа TIGER. В ней семантические идентификаторы (SIDs) формировались через RQ-VAE поверх текстового описания товара (эксперименты были на открытых датасетах Amazon). В PLUM к этому подходу добавляют коллаборативный сигнал и мультимодальные контентные представления. Используются уже готовые аудио-, видео- и текстовые эмбеддинги YouTube, которые конкатенируются и проходят через энкодер RQ-VAE.
Новые предложенные компоненты:
— Multi-Resolution Codebooks: число идентификаторов в кодбуках уменьшается от слоя к слою, чтобы верхние уровни разделяли крупные семантические категории, а нижние — более гранулярные признаки.
— Progressive Masking: модель обучается восстанавливать не полный набор SIDs, а его префикс.
Ключевая вещь в архитектуре — дополнительный contrastive learning на RQ-VAE, который вводит коллаборативный сигнал прямо в процесс токенизации. Берутся пары айтемов, встречавшихся рядом в пользовательской истории как позитивные пары, обучается с помощью InfoNCE по батчу. Так коллаборативный сигнал тоже участвует в формировании кодбуков без отдельной стадии дообучения как, например, в OneRec. В итоге SIDs начинают отражать не только контентную информацию об айтемах, но и коллаборативные пользовательские связи между ними.
2) Continued Pre-Training (CPT). Здесь языковая модель дообучается с увеличенным словарём, в который, помимо изначальных токенов, встроены токены айтемов. Модель обучается на смешанной задаче (supervised + self-supervised). Цель этой стадии — заставить LLM встроить в общее семантическое пространство представления токенов и SIDs.
3) Task-Specific Fine-Tuning. Это полноценное обучение на задачу генеративного ретривала: модель предсказывает релевантные айтемы в пользовательских историях (обучение на next token prediction).
В целом идея PLUM строится на прямой аналогии между словами в языковых моделях и айтемами в RecSys: если в NLP слова токенизируются для работы с огромным словарём, то в рекомендациях можно аналогично токенизировать айтемы.
Эксперименты и результаты
Основная модель — Mixture-of-Experts с ~900 млн активных параметров (всего 4,2 млрд).
В онлайн-A/B-тестах PLUM показывает рост ключевых метрик: CTR и вовлечённости пользователей, особенно в коротких видео (YouTube Shorts). Аблейшены подтверждают, что важны все предложенные компоненты.
В работе показывают законы масштабирования для предложенного фреймворка: при увеличении размера моделей при разном фиксированном вычислительном бюджете ошибки на обучении и валидации снижаются, но самые большие модели (около 3 млрд активных параметров, 20 млрд всего) пока упираются в ограничения вычислительных ресурсов. Исследователям не хватило времени, данных и мощностей, чтобы хорошо обучить модели такого размера, однако инженеры считают, что при дальнейшем масштабировании качество может вырасти ещё больше.
Финальная PLUM-модель дообучается ежедневно на ~0,25 млрд примеров, тогда как предыдущие LEM (Large Embedding Models) подходы требовали многомиллиардных датасетов.
@RecSysChannel
Разбор подготовил