Сегодня начинаем разбирать неожиданно вышедшую статью MiniOneRec. В ней использованы подходы из нашумевшей серии техрепортов OneRec от Kuaishou. Авторы MiniOneRec — исследователи из университетов Китая и Сингапура — фактически берут ключевые идеи OneRec, переносят их в минимально жизнеспособный фреймворк и подтверждают, что они действительно работают на открытых данных. Это выглядит как попытка «повторить OneRec», но в академии и без доступа к приватным датасетам. И действительно, LLM-подходы в NLP работают слишком хорошо, чтобы не пытаться перенести их в другие домены — в том числе в рекомендации.
Семантические ID и подготовка данных
Первое препятствие, которое сразу появляется в рекомендациях, — огромный каталог документов. Нельзя просто взять LLM и обучить её поверх ID в десятки или сотни миллионов: embedding/de-embedding-слои и softmax станут непригодными. Поэтому MiniOneRec, как и OneRec, используют семантические ID из работы TIGER.
Суть простая: каждый документ кодируется короткой последовательностью токенов. Из исходного текста (название + описание) получают эмбеддинг: текст прогоняется через замороженную Qwen3-Embedding-4B, затем hidden states последнего слоя усредняются (mean pooling) в один вектор, который и подаётся в трёхуровневую RQ-VAE-кластеризацию. На каждом уровне отнимается ближайший из 256 центроид (получается semantic_id_0), формируется остаток, который проходит ту же процедуру кластеризации следующего уровня — в итоге документ получает трёхтокенную семантическую подпись. Это резко уменьшает словарь: вместо миллионов ID становится 3x256 дополнительных к словарю токенов. У Tiger и OneRec эта идея ключевая, и MiniOneRec полностью повторяет её.
Авторы также отмечают проблему коллапса кластеров (слишком много документов в одном кластере), поэтому в коде используют не случайную инициализацию, а RQ k-means из оригинального OneRec. Это увеличивает энтропию кластеров и улучшает токенизацию.
SFT и перенос NLP в рекомендации
После токенизации авторы делают SFT поверх предобученной LLM (берут Qwen). В случае с академией это более чем оправдано: экономятся ресурсы, не нужно тренировать архитектуру с нуля и сразу есть сильный старт. Истории пользователя подаются в виде последовательностей семантических токенов, а модель учится предсказывать следующий айтем.
В этот процесс также привносят новизну вида алайнмента между NLP и рекомендациями. Авторы подмешивают в обучение разные форматы примеров, с тем чтобы перенести world knowledge модели на новые токены.
Получается несколько типов задач:
- история на естественном языке — нужно предсказать следующий айтем в виде семантических токенов;
- история в виде семантических токенов — нужно предсказать текстовое описание следующего айтема;
- просто перевод айтема между двумя представлениями — из текста в семантические токены и наоборот.
Этот шаг даёт самый большой прирост качества. В аблейшенах видно, что это важнее, чем стартовать со случайных весов. Вместе с тем сама идея достаточно проста: смешивать рекомендации с задачами NLP, чтобы модель лучше экстраполировала знания. Это похоже на недавнюю работу от Google — PLUM, хотя авторы на неё не ссылаются (возможно результаты получены параллельно).
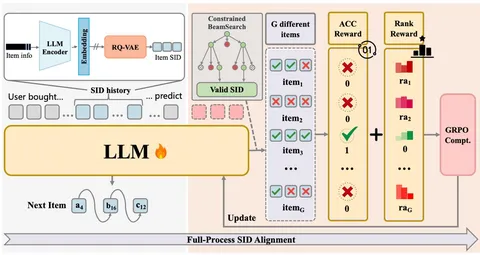
В следующей части обзора расскажем о RL-дообучении, масштабировании и результатах.
@RecSysChannel
Разбор подготовил