Завершаем разбор статьи MiniOneRec. В первой части обсуждали SFT и семантические ID, а теперь посмотрим, что происходит дальше: RL-дообучение, генерация траекторий и насколько авторы смогли воспроизвести индустриальные результаты на открытых данных.
RL-дообучение: GRPO и генерация траекторий
После SFT и алайнмента применяется reinforcement learning по аналогии с OneRec — используется GRPO. Модель уже умеет генерировать последовательности семантических токенов, каждая из которых соответствует айтему. Генерируются несколько траекторий (beam search или dynamic sampling), затем по каждой считается награда. Награда включает два компонента: корректность следующего айтема и ранжирование согласно frozen collaborative модели (SASRec в реализации авторов).
Чтобы модель генерировала только валидные токены, используется constrained beam search: логиты, не соответствующие существующим айтемам из кодбука, маскируются. То есть стратегия гарантирует, что каждая сгенерированная последовательность соответствует реальному айтему.
GRPO здесь в «ванильной» версии: есть ограничение на отклонение от начальной политики, чтобы избежать reward hacking — классического случая, когда модель накручивает награду, но начинает генерировать бесполезные последовательности.
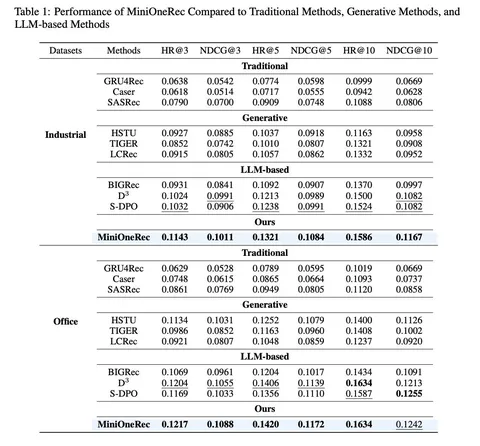
Результаты и масштабирование
Авторы говорят о законе масштабирования: модели большего размера достигают лучшего качества (меньше лосс). Но есть важный момент: все модели обучаются одинаковое количество эпох на одном и том же датасете. Нет параметризации по количеству данных, а значит это не полноценный закон масштабирования, а скорее наблюдение: «большая модель лучше маленькой». С другой стороны, до этой работы таких результатов на открытых датасетах не было — и это важное подтверждение работоспособности индустриальных подходов вне Kuaishou.
В целом, MiniOneRec повторяет ключевые идеи OneRec — но делает это на открытых данных, с полностью доступным кодом и понятными экспериментами. Авторы аккуратно воспроизводят семантическую токенизацию Tiger, SFT поверх LLM, алайнмент между NLP и рекомендациями и RL-дообучение через GRPO. Это первая попытка показать, что индустриальные результаты действительно можно повторить за пределами приватных данных.
@RecSysChannel
Разбор подготовил