Скейлинг рекомендательных моделей — один из ключевых трендов рексистем последних лет. Исследователи Яндекса в рамках подхода Argus показывали, что качество моделей сильнее всего растёт при увеличении длины последовательности, которую обрабатывает трансформер. Однако рост до десятков и сотен тысяч событий сопряжен уже с инфраструктурными сложностями, и применение таких моделей в реалтайме за разумное время не представляется возможным.
Сегодня рассказываем о статье, в которой авторы из Meta* предлагают элегантный двухстадийный фреймворк. Вместо того, чтобы тяжелым трансформером держать в контексте 1 млн событий, можно в офлайне сжать всю lifelong-историю, а в рантайме использовать это сжатое представление.
Идея сама по себе не нова, но в близких по духу работах SIM, TWIN V2 или Transact V2 утилизация lifelong-контекста была сопряжена либо с тривиальным и неэффективным сжатием последовательности, либо с обработкой ограниченного подмножества событий, что в итоге ведёт к сильной просадке качества.
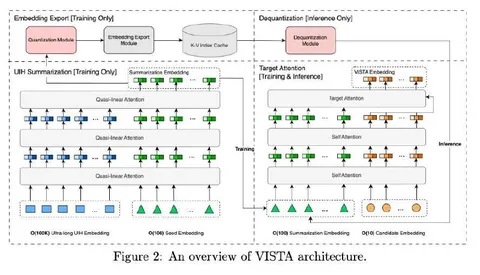
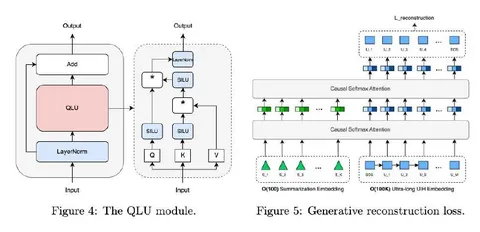
В статье сжатие истории проводят так: берётся полная история пользователя, над которой строят квазилинейный аттеншн, и вводят ряд суммаризирующих эмбеддингов — рассматривают до 128 штук. Модифицированный аттеншн помогает обрабатывать сверхдлинные последовательности за разумное время, а нелинейность, введенная с помощью SiLU, позволяет лучше моделировать сложные взаимодействия. Для эффективного сжатия истории авторы также вводят дополнительный reconstructive loss, чтобы из полученных эмбеддингов можно было как можно лучше восстановить исходную последовательность.
Эмбеддинги складываются в кэш, который обновляется асинхронно. Во время инференса их берут и строят target attention между сжатыми представлениями и айтемами-кандидатами.
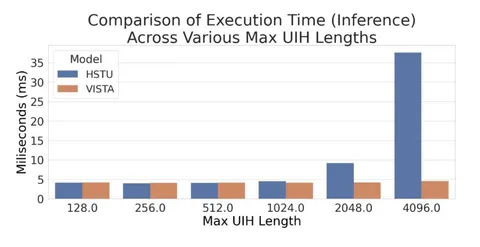
Результаты офлайн-экспериментов оказались примерно сопоставимы с HSTU, вместе с этим скорость инференса при увеличении длины последовательности остаётся практически константной.
A/B-тест проводился, скорее всего, на базе Reels, в качестве бейзлайна выступала HSTU-модель. Ключевая внутренняя метрика вовлеченности C-task выросла на 0,5%, а дополнительные метрики удержания — O1 и O2 tasks — на 0,2% и 0,04%. Утверждается, что рост O2 даже на 0,01% — это существенный успех.
@RecSysChannel
Разбор подготовил
___
Компания Meta признана экстремистской; её деятельность в России запрещена.