Сегодня кратко пересказываем техрепорт от Kuaishou о рекомендательной модели, которая должна быть способна не только рекомендовать, но ещё и понимать, что она рекомендует, и уметь это объяснять.
Авторы исходят из проблемы, что современные рекомендательные модели учатся и применяются на узком срезе данных, что мешает им приобретать общие знания и масштабироваться, как большим языковым моделям. Для преодоления этого разрыва предлагают бенчмарк, открытый датасет и семейство опенсорсных моделей.
RecIF-Bench
В бенчмарке три домена: short video, ads и products. Всего около 200 тысяч пользователей, больше 15 миллионов айтемов и почти 120 миллионов взаимодействий. Домены при этом сильно отличаются.
В видео у пользователей очень длинные истории с сотнями взаимодействий. В рекламе айтемов и кликов меньше. Products — это отдельный e-commerce-домен со своими паттернами.
Для кодирования айтемов используется семантические id, которые добавляются в словарь базовой LLM. История пользователя в виде единой последовательности, а обучение просходит авторегрессивно. Это позволяет обучать архитектуру LLM без изменений по принципу next-token prediction, но в рекомендательном контексте.
Кроме логов взаимодействий, датасет содержит три источника информации: пользователь, айтем и само взаимодействие. Пользователь описывается через текстовый User Portrait: демография, история просмотров, поиски, подписки, покупки и т.д. У айтемов есть мультимодальные эмбеддинги и dense captions (для видео). Во взаимодействиях учитывают разные сигналы: лайки, комментарии, просмотры, дизлайки.
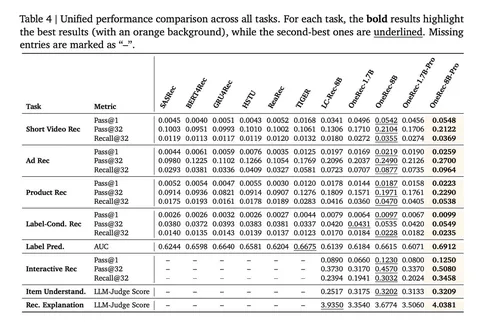
Какие задачи проверяют
Всего выделяют восемь типов задач и распределяют их по четырём уровням. Каждый следующий требует от модели более «общего» поведения. Сначала понимание айтемов и простые рекомендации. Потом условные рекомендации, вроде «предскажи видео, которое лайкнут». И в конце задачи на объяснение рекомендаций.
Как обучают модель
Обучение во многом похоже на OneRec Think. Сначала делают warm-up для айтемных токенов, потом претрейн на основном датасете с добавлением обычных текстов, чтобы предотвратить катастрофическое забывание языка. Полностью это всё равно не спасает, поэтому дальше идут стадии посттрейнинга.
В посттрейне главная стадия — восстановление текстового рассуждения. Модель дистиллируют из замороженной Qwen и обучают не генерировать айтемные токены в обычных текстовых вопросах. В самом конце добавляют RL-стадию, чтобы улучшить рекомендации.
Отдельно говорят о масштабировании, что для таких моделей данные нужно скейлить чуть агрессивнее, чем параметры. Это хорошо ложится на общий опыт обучения рекомендательных моделей: относительно небольшие модели учатся на больших датасетах.
Результаты
На своём бенчмарке модели ожидаемо обгоняют базлайны. Интересно, что есть трейд-офф между обычной 8B и 8B Pro: вторая лучше в рекомендациях, но обычная 8B часто сильнее в задачах, где нужно говорить и объяснять.
На Amazon-бенчмарках тоже показывают хорошие цифры, но эти эксперименты по сути нельзя воспроизвести, так как слишком много закрытых деталей и дополнительного дообучения.
@RecSysChannel
Разбор подготовил