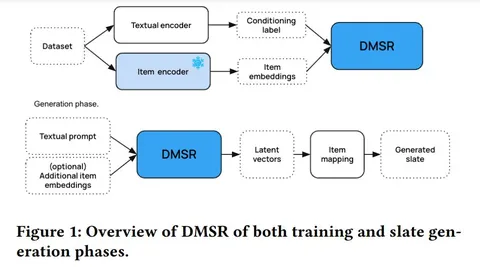
Разбираем свежую статью от Spotify о диффузионных моделях для рекомендации слейтов. Слейт — что-то вроде списка событий произвольной длины. Самый простой пример слейта — плейлист с музыкой. Особенность таких рекомендаций в том, что помимо генерации кандидатов для показа необходимо ещё и ранжирование, так мы получаем пачку, внутри которой объекты должны быть расположены в определённом порядке. В идеале с приносящем как можно больше удовольствия пользователю.
Ранжирование объектов — важная подзадача в рамках рекомендации слейтов, и для её решения авторы статьи используют отдельные модели, но в данной работе концентрируются на retrieval-части, рассказывая, чем хороши диффузионки. В качестве примеров похожих работ они ссылаются на 2 статьи от Google, за 2015 и 2019 год, где для решения аналогичной задачи используется RL. Проблема в том, что айтемы в слейте являются в RL-подходе независимыми событиями. Это упрощает обучение, но такой подход не совсем корректен, так как зависимость между соседними айтемами в слейте все же есть, что приводит к проблемам с качеством генерации.
Исследователи из Spotify утверждают, что генеративный подход (а именно — диффузионные модели) могут работать лучше, чем RL-like подходы. Диффузионки могут сделать слейт разнообразнее благодаря неявному пониманию, что айтемы не должны быть слишком похожими. Также авторы замечают, что диффузионные модели помогают бороться с popularity bias’ом и включать в подборки менее очевидные треки даже без явного обучения под эту задачу. Также авторы делают conditioning на весь контекст — профиль и запрос пользователя. Опционально в контекст добавляют отдельные айтемы из слейта, которые уже были предсказаны.
По словам исследователей, такой метод даёт значимо лучшие результаты, чем RL и другие привычные решения в сфере рекомендаций слейтов.
@RecSysChannel
Разбор подготовил