Эта статья о том, как с помощью знаний о пользователе с разных доменов бустить качество CTR-модели на домене основном.
Просто собрать данные с разных доменов в одном месте и централизованно обучить модель не получится — это не конфиденциально. Для того чтобы безопасно обрабатывать чувствительные данные, существует подход Vertical Federated Learning (VFL): обучение происходит на каждом домене по отдельности, а полученные верхнеуровневые представления собираются в общую модель.
Но есть нюанс: собрать таким образом можно только выровненные представления (aligned data). Авторы статьи предлагают, как утилизировать на основном домене unaligned data — данные, к которым почему-то не получилось присоединить полезную информацию с других доменов.
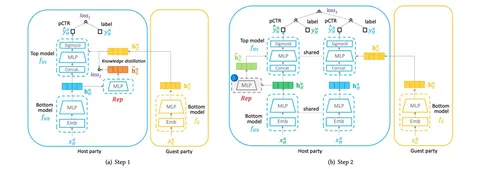
Для aligned data обучение будет состоять из двух фаз (как на схеме):
1. На каждом домене своя сетка получит эмбеддинг пользователя, после чего передаст его сетке главного домена (вместо сырых данных — высокоуровневые представления). Эмбеддинг главного домена копируется на две головы.
2. Первая голова пытается выучить эмбеддинг другого домена. Происходит дистилляция: эмбеддинг главного домена проходит через MLP и через MSE сближается с эмбеддингом второстепенного домена (или доменов). Во второй голове эмбеддинг из главного и второстепенного доменов конкатятся, прогоняются через MLP и идут в BCE loss.
Когда готова голова, которая предсказывает эмбеддинг с другого домена, можно обучаться и на unaligned data: только во второй голове вместо эмбеддинга с другого домена используется эмбеддинг, предсказанный дистилляционной головой.
Результаты подтверждаются офлайн-экспериментами на открытом и приватном датасетах. Ориентируясь на AUC и LogLoss, авторы сравнивают предложенный подход:
— с другими VFL-моделями (которые используют как aligned, так и aligned + unaligned данные);
— с Wide&Deep (без кросс-домена).
@RecSysChannel
Разбор подготовил