Сегодня делимся статьёй о резком переобучении CTR-моделей в начале второй эпохи, a.k.a. one-epoch phenomenon.
Этой проблеме подвержены модели со структурой вида categorical features with large sparsity ➡️ Embedding ➡️ MLP.
Чтобы понять, можно ли справиться с феноменом, авторы всесторонне его анализируют. Так, на качество обучения CTR-моделей не влияют:
— число параметров модели;
— вид функций активации и батч сайз;
— weight decay и dropout (без dropout, кстати, лучше).
Из-за чего же тогда могут переобучаться модели? По результатам экспериментов, есть несколько причин:
— Оптимизаторы. Чем быстрее сходимость, тем сильнее отрицательное влияние на обучение. Наиболее подвержены эффекту Adam и RMSPROP.
— Высокие LR: эффект наблюдается только если они больше 10⁻⁷.
— Кардинальность фичей. Чем меньше уникальных эмбеддингов, тем слабее эффект. Авторы рассматривали FILTER (использовали m% эмбеддингов наиболее частых ID, остальные — в один эмбеддинг), Hash (создавали табличку с m% строк от общего числа ID, далее — хэшировали ID в эмбеддинги).
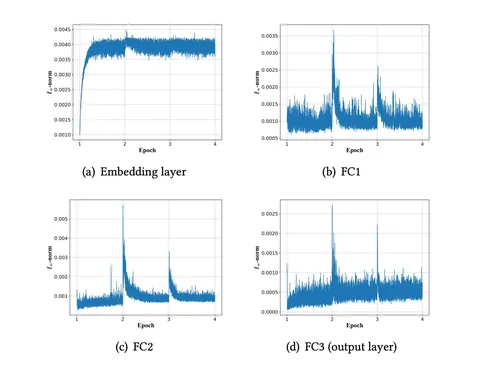
Обязательное условие one-epoch феномена — сдвиг между распределениями p(x_{trained}, y) и p(x_{untrained}, y), вызванный обучением на фичах высокой кардинальности, например, ID товаров. Если этот сдвиг есть, модель поверх эмбеддинг-слоёв моментально переобучается под p(x_{trained}, y).
На картинках показаны нормы изменений параметров слоёв. Легко заметить, что в начале второй эпохи резко меняются параметры слоёв поверх эмбеддингов. Это доказывает разницу в распределениях p(x_{trained}, y) и p(x_{untrained}, y).
Можно, конечно, просто не использовать эмбеддинги товаров, чтобы избежать переобучения, но это сильно просадит пиковое качество. Вывод авторов — обучать CTR-модели лучше в одну эпоху.
@RecSysChannel
Разбор подготовил