Сегодня разбираем не новую, но важную статью на тему scaling law в RecSys. В домене NLP он сводится к идее: чем больше модель, тем выше её качество. Но в современных рекомендательных системах нет такой явной зависимости. Мотивация авторов в том, чтобы создать архитектуру, которая, прежде всего, хорошо масштабируется по параметрам.
Исследователи утверждают, что достигли своих целей:
1) создали архитектуру, которая позволяет улавливать сложные взаимодействия признаков высокого порядка;
2) добились плавного масштабирования качества в зависимости от размера датасета, объёма вычислений (GFLOP) и ограничений по параметрам.
В статье по большей части рассматривают подход sparse scaling, суть которого в том, чтобы добавить множество эмбеддингов и за счёт этого масштабироваться по числу параметров. Однако это не совсем то, к чему стремятся авторы, по двум причинам. Первая: если просто добавить много новых эмбеддингов, не будут улавливаться нетривиальные взаимодействия. Вторая: при таком подходе не используется потенциал современных GPU, а только задействуется дополнительная видеопамять.
Ключевая инновация статьи — использование серии последовательно расположенных факторизационных машин (Factorization Machines, FMB). Это как раз и позволяет учитывать нетривиальные взаимодействия высоких порядков.
Общую схему архитектуры можно описать так: сначала берутся Dense embeddings — это преобразование всех признаков в эмбеддинги. Затем следует блок Interaction Stack, состоящий из нескольких Wukong-слоёв, каждый из которых разделён на два простых блока: Factorization Machine Block и Linear Compress Block.
Interaction Modules Stack состоит из l одинаковых слоёв (interaction layers), причём каждый слой постепенно захватывает всё более высокие порядки взаимодействия признаков. Для слоя i cтека его результаты могут содержать взаимодействия признаков произвольного порядка от 1 до 2i.
Авторы указывают, что чем важнее фича, тем большая размерность эмбеддинга ей выделяется. Затем все эти эмбеддинги объединяют, конкатенируют и через MLP преобразуют в d-dimensional векторы.
На внутреннем датасете исследователей насчитывается около семисот фич, среди которых есть не только категориальные, но и Dense-фичи. Их тоже пропускают через MLP, чтобы привести к одинаковым представлениям. Получив эти эмбеддинги, авторы переходят к следующему слою.
Также авторы пишут, что используют собственную оптимизированную версию факторизационных машин. Отмечается, что в большинстве современных датасетов число фичей ощутимо больше размерности эмбеддингов. Поэтому они вводят определённые упрощения, которые нацелены на оптимизацию вычислительных затрат, а не на улучшение качества. Но в целом FMB можно считать околодефолтными.
Также в статье рассказывается, как именно можно масштабировать предложенную архитектуру. Во-первых, можно увеличить число слоёв в блоке Interaction Stack. Во-вторых, допускается повышение размерности эмбеддингов, которые генерируются каждой внутренней компонентой. Наконец, авторы отмечают, что можно настраивать гиперпараметры, чтобы сбалансировать производительность и качество модели.
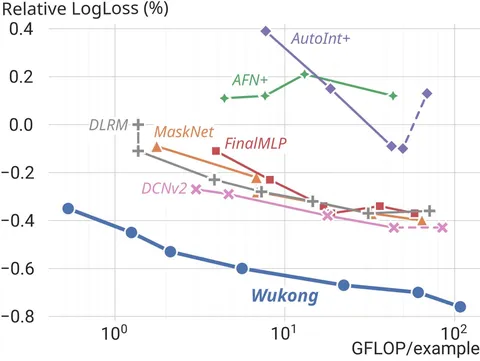
В финале авторы показывают результаты на шести общедоступных датасетах: по метрике AUC модель почти везде превосходит другие решения. При этом по LogLoss на ряде датасетов (особенно там, где высокая вариативность) Wukong не всегда занимает первое место.
В целом, полученное решение действительно показывает поведение, близкое к scaling law: при увеличении числа параметров и размера датасета качество предсказаний закономерно возрастает.
@RecSysChannel
Разбор подготовил