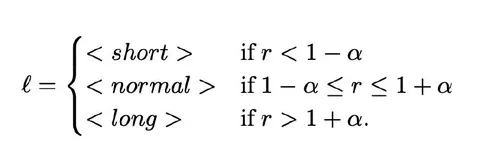Сегодня делимся подборкой трёх концептуально интересных работ про обучение speech-моделей. Первая — о контроле генерации на этапе декодирования, две остальные — о том, как аккуратнее стыковать речь и текст и обучать мультимодальные системы.
Length Aware Speech Translation for Video Dubbing
Авторы решают понятную боль: как управлять длиной выходной последовательности (перевода), а не полагаться на эвристики поверх beam search (например, штрафы/нормализации за длину). Нюанс таких эвристик в том, что они часто смещают ранжирование в сторону более коротких или более длинных гипотез.
В статье предлагают разбить генерацию на несколько режимов длины: short, normal, long. Вместо стандартного стартового токена (BOS/SOS) декодирование начинается со специального length-тега, и при обучении модель видит такие же теги — в итоге можно явно попросить «короткий» или «длинный» перевод.
Отдельно авторы модифицируют beam search: обычно на шаге прунинга оставляют top-k гипотез по скору. А тут при каждом прунинге стараются сохранять минимум по одной гипотезе каждого типа. Это важно для случаев, когда «длинная» ветка обычно не доживает до конца: модель быстро завершает декодирование на коротких вариантах, а потом может выясниться, что более длинный — был бы лучше.
Очевидный минус подхода: поддержка длинных гипотез — это дополнительные затраты по производительности, потому что генерация идёт дольше. Но сама идея «контролируем длину явно и держим разные длины в beam search» выглядит практичной.
Scheduled Interleaved Speech-Text Training for Speech-to-Speech Translation with LLMs
Предположим, у нас есть текстовая LLM, и мы хотим научить систему работать и со звуком. Лобовой вариант — сразу добавить аудио в обучение и перейти в speech-режим. Но такой переход получается слишком резким: до этого модель обучалась только на тексте, а теперь получает аудиопредставления, и на этом стыке всё легко может развалиться.
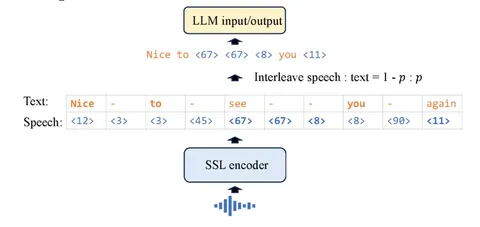
Чтобы этого избежать, текст обычно не убирают сразу, а продолжают подавать его вместе с аудио, постепенно меняя пропорции: сначала почти один текст и немного аудио, потом аудио становится больше, текста меньше — и так далее, вплоть до режима «почти только аудио».
Здесь авторы пошли ещё дальше и делают это не на уровне целых примеров, а внутри одного сэмпла: часть токенов — текстовые, часть — аудио. За счёт этого переход получается ещё мягче: сначала в сэмпле почти один текст и немного аудио, потом аудио всё больше. В конце для таких смешанных примеров остаётся только аудио, а также чисто текстовые примеры.
Text-Enhanced Audio Encoder for Large Language Model based Speech Recognition via Cross-Modality Pre-training with Unpaired Audio-Text Data
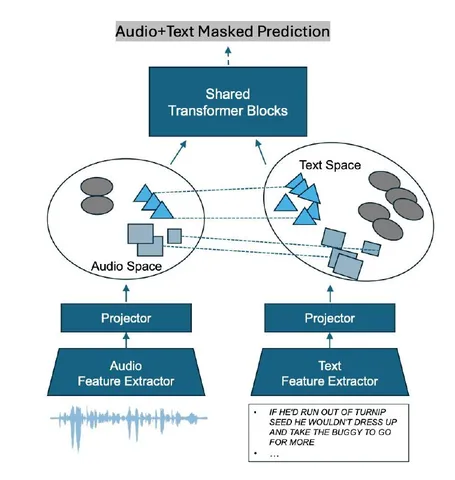
Можно отдельно обучать аудиоэнкодер и отдельно — языковую модель, но дальше аудиочасть и LLM всё равно нужно «поженить». Авторы хотят сделать этот стык более гладким: чтобы при совмещении ничего не развалилось и текстовая часть LLM не деградировала.
Логика такая: выход аудиоветки дальше подаётся на вход LLM. Авторам важно, чтобы этот вход по форме и свойствам был ближе к тому, к чему LLM привыкла в текстовом режиме. Поэтому они добавляют отдельную текстовую ветку и общую часть — shared transformer blocks. Эти общие блоки обучаются на текстовом сигнале, за счёт этого выходы аудио- и текстовой веток становятся ближе по представлению, так что LLM проще работать с аудиовыходом.
Новизна тут скорее в подходе к обучению: вместо полностью раздельной тренировки (когда батчи идут либо аудио-, либо текстовые) в работе допускают совместное использование аудио и текста в одном батче — и за счёт этого обучение получается более стабильным.
Евгений Ганкович