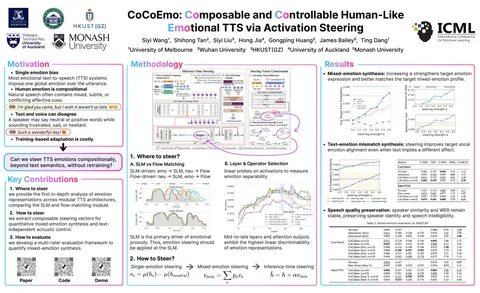
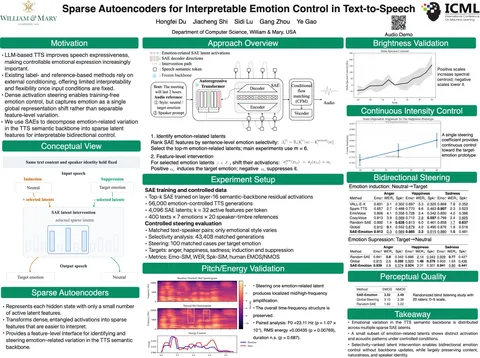
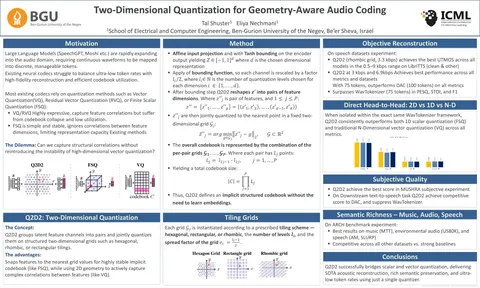
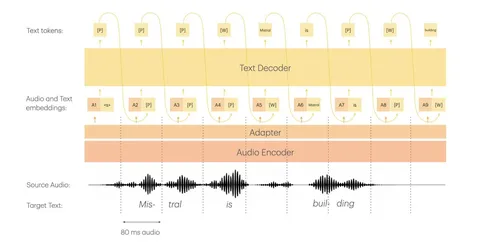
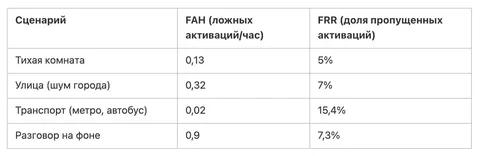
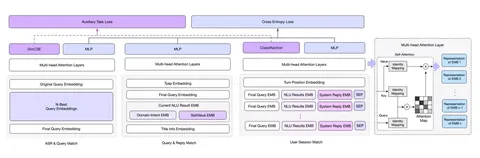
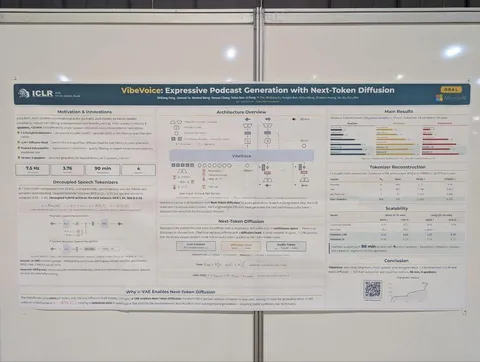
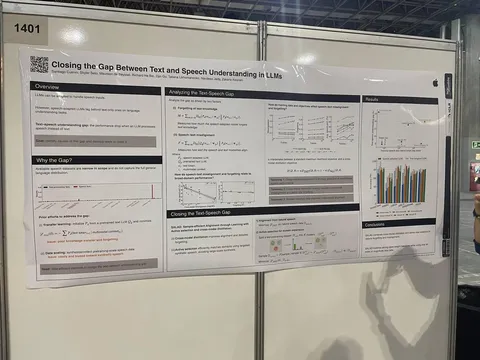
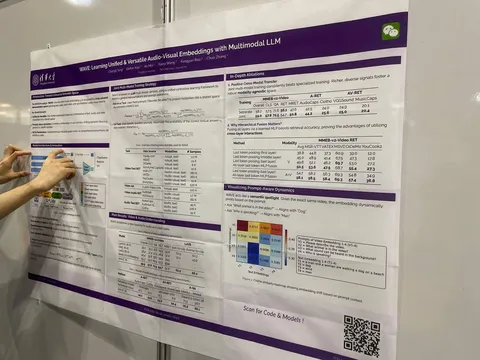
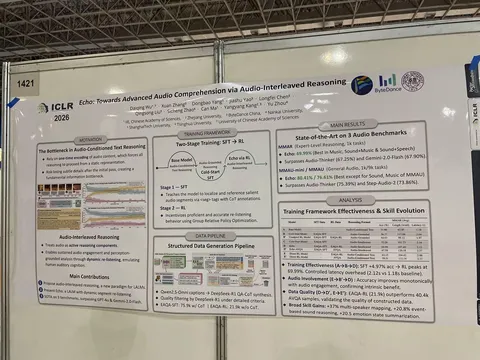
A review on subjective and objective evaluation of synthetic speech
Сегодня разбираем обзор 2024 года, авторы которого попытались охватить 40 с лишним лет эволюции оценки синтеза речи — с 80-х и до наших дней. При этом статья не такая уж большая: 27 страниц, 7 из которых — ссылки на множество упомянутых работ.
Первая часть, пожалуй, самая увлекательная — историческая справка о том, как оценивали синтез речи с самого зарождения. Вторая часть — о предсказателях MOS и моделях, которые это делают. Мы сегодня посмотрим на первую часть.
80-е: разборчивость как главная метрика
В этот период краудсорса ещё нет и всё делается в лабораториях, люди буквально от руки записывают, что услышали. Главная метрика — доля распознанных слов.
Используются тесты MRT (Modified Rhyme Test) и DRT (Diagnostic Rhyme Test), когда услышанное слово выбирают среди рифмованных вариантов. В DRT берутся пары, отличающиеся одним признаком, например «звонкий/глухой».
Также используют SUS (Semantically Unpredictable Sentences) — грамматически верные, но бессмысленные фразы. Тем самым хотят убрать контекст, чтобы мозг не достраивал «замамбленное» слово по смыслу.
Интересно, что датасеты собирали по фонетическим свойствам, таким как назальность, шипение, протяжность, плотность — такое хочется попробовать переиспользовать.
90-е–2000-е: фокус на натуральность
Появились unit-selection и HMM и сделали речь разборчивой. Главный вопрос сместился, и теперь во главе угла естественность (метрика, которая с нами уже 30 лет и никуда не делась).
В этот же период появился MOS (ITU-T P.800), пятибалльная шкала ACR, что становится стандартом индустрии. Следом появляется протокол P.85 — мульти-шкальная оценка, которая включает произношение, listening effort и даже приятность голоса (уже в 1996-м!).
Интересно проследить судьбу слайдерных шкал. В 90-е их захейтили как смещённые и нерепрезентативные, а уже в следующее десятилетие начали использовать очень активно.
Другая веха — Blizzard Challenge, который с 2005 года зафиксировал ещё один индустриальный стандарт, включающий MOS + транскрипцию обычных предложений и SUS + слова из MRT/DRT-категорий.
2010-е и сейчас: MOS упёрся в потолок
Системы стали почти неотличимы от записи, и MOS перестал различать близкие модели. Стали нужны более чувствительные тесты. Возвращается непрерывная шкала — это MUSHRA со скрытым референсом и якорями для нормировки (если в среднем ставишь чуть выше, твои значения нормируются).
Благодаря краудсорсингу (CrowdMOS) оценка, наконец, выбирается за пределы лабораторий. Также появляется DMOS (differential MOS) — оценка пары «референс-тест». Pairwise и side-by-side окончательно приживаются. А в 2007-м в шкалы добавляют человечность: эмоции, манеру, tone of voice.
Несколько идей, которые хочется попробовать
🔴 Для надёжных MOS-результатов (Blizzard 2013) требуется от 30 слушателей. Если использовать меньше, оценка может быть слишком субъективной.
🔴 Лейблы MOS нелинейные. Расстояния между категориями неравномерны, и вместо равномерных весов в аспектном замере можно взять веса из исследований.
🔴 Слушателю полезно давать не голый текст, а контекст и задачу — это заметно меняет оценки.
🔴 Неожиданностью стало, что более детальная инструкция не всегда улучшает согласованность, иногда люди следуют своему мнению более согласованно, чем подробным правилам.
🔴 Таксономия фонетических ошибок из 80-х (назальность, шипение, протяжность, плотность) может пригодиться, чтобы классифицировать проблемы синтеза, а не описывать их разрозненными «мамблит» и «путает з-с».
Ольга Архипова❣️ Специально для Speech Info
Сегодня разбираем обзор 2024 года, авторы которого попытались охватить 40 с лишним лет эволюции оценки синтеза речи — с 80-х и до наших дней. При этом статья не такая уж большая: 27 страниц, 7 из которых — ссылки на множество упомянутых работ.
Первая часть, пожалуй, самая увлекательная — историческая справка о том, как оценивали синтез речи с самого зарождения. Вторая часть — о предсказателях MOS и моделях, которые это делают. Мы сегодня посмотрим на первую часть.
80-е: разборчивость как главная метрика
В этот период краудсорса ещё нет и всё делается в лабораториях, люди буквально от руки записывают, что услышали. Главная метрика — доля распознанных слов.
Используются тесты MRT (Modified Rhyme Test) и DRT (Diagnostic Rhyme Test), когда услышанное слово выбирают среди рифмованных вариантов. В DRT берутся пары, отличающиеся одним признаком, например «звонкий/глухой».
Также используют SUS (Semantically Unpredictable Sentences) — грамматически верные, но бессмысленные фразы. Тем самым хотят убрать контекст, чтобы мозг не достраивал «замамбленное» слово по смыслу.
Интересно, что датасеты собирали по фонетическим свойствам, таким как назальность, шипение, протяжность, плотность — такое хочется попробовать переиспользовать.
90-е–2000-е: фокус на натуральность
Появились unit-selection и HMM и сделали речь разборчивой. Главный вопрос сместился, и теперь во главе угла естественность (метрика, которая с нами уже 30 лет и никуда не делась).
В этот же период появился MOS (ITU-T P.800), пятибалльная шкала ACR, что становится стандартом индустрии. Следом появляется протокол P.85 — мульти-шкальная оценка, которая включает произношение, listening effort и даже приятность голоса (уже в 1996-м!).
Интересно проследить судьбу слайдерных шкал. В 90-е их захейтили как смещённые и нерепрезентативные, а уже в следующее десятилетие начали использовать очень активно.
Другая веха — Blizzard Challenge, который с 2005 года зафиксировал ещё один индустриальный стандарт, включающий MOS + транскрипцию обычных предложений и SUS + слова из MRT/DRT-категорий.
2010-е и сейчас: MOS упёрся в потолок
Системы стали почти неотличимы от записи, и MOS перестал различать близкие модели. Стали нужны более чувствительные тесты. Возвращается непрерывная шкала — это MUSHRA со скрытым референсом и якорями для нормировки (если в среднем ставишь чуть выше, твои значения нормируются).
Благодаря краудсорсингу (CrowdMOS) оценка, наконец, выбирается за пределы лабораторий. Также появляется DMOS (differential MOS) — оценка пары «референс-тест». Pairwise и side-by-side окончательно приживаются. А в 2007-м в шкалы добавляют человечность: эмоции, манеру, tone of voice.
Несколько идей, которые хочется попробовать
Ольга Архипова
291 просмотров · 17 реакций
Открыть в Telegram · Открыть пост на сайте