Сегодня разбираем статью о том, как бороться с систематическими ошибками псевдолейблинга в ASR.
Аудиоданных разных доменов существует огромное количество, но для конкретных задач (например, редких акцентов) разметки часто нет. Сбор качественных транскрипций стоит дорого и занимает много времени. В таких случаях выходом становится псевдолейблинг: сначала модель обучают на размеченных данных, потом она сама делает псевдолейблы для неразмеченных, а дальше модель дообучают уже на них.
Проблема в том, что псевдолейблинг даёт разметку, далекую от совершенства, — с ошибками и байесами. И если модель учится на этом итеративно, ошибки не исчезают, а накапливаются. В итоге появляются устойчивые паттерны, которые не лечатся простым уменьшением шума или confidence-фильтрацией.
Главный вопрос статьи такой: как уменьшить систематические ошибки псевдолейблинга, если в target-домене вообще нет ground truth?
Идея авторов — использовать task arithmetic. В упрощённом виде это выглядит так:
1. Берём предобученную ASR-модель и файнтюним её на source-домене с настоящей разметкой.
2. Отдельно обучаем модель на псевдолейблах source-домена.
3. Вычитаем параметры одной модели из другой и получаем correction vector — вектор, который описывает, что именно «портит» обучение на псевдолейблах.
Дальше этот correction vector добавляют при адаптации модели на target-домене, где есть только псевдолейблы. Смысл в том, чтобы при дообучении на псевдолейблах модель меньше перенимала их систематические ошибки.
В статье это показывают на примере смены акцентов: target-домен — это акценты, которых не было в source-домене. В экспериментах используют AfriSpeech-200 — датасет, в котором люди из африканских стран на английском языке с заметными акцентами наговаривают тексты на медицинскую и общую тематику.
Также в работе рассматривают вариант метода с subgroup correction. Вместо одного общего correction vector строят отдельные векторы для разных групп спикеров, а затем усредняют их и используют при адаптации модели к target-домену.
Эксперименты проводят через кросс-валидацию по акцентам: часть акцентов используют как source-домен, остальные — как target-домен, и так по всем разбиениям.
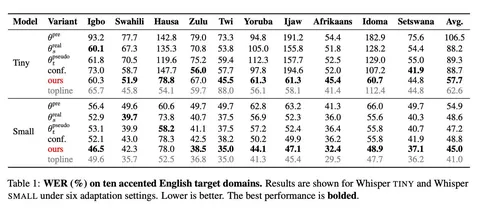
В таблице с результатами сравнивают несколько сценариев. Выводы следующие:
- Предобученная модель (zero-shot) на новых акцентах даёт высокий WER.
- Стандартный псевдолейблинг (файнтюн на сгенерированной разметке) значительно улучшает качество, но наследует систематические ошибки учителя.
- Confidence-based filtering (отсев неуверенных предсказаний) даёт лишь небольшой прирост и не решает проблему закрепившихся паттернов ошибок.
- Pseudo2Real показывает существенное снижение WER против обычного псевдолейблинга (до 35% относительного улучшения на Whisper Tiny).
- Pseudo2Real-SC (Subgroup Correction) с кластеризацией спикеров даёт дополнительный прирост качества (в среднем ещё на 4–6%), особенно эффективно исправляя ошибки на самых сложных акцентах (например язык хауса), так как учитывает разнообразие дикторов.
- Topline (обучение на реальной разметке target-домена) — теоретический «потолок» качества. Однако авторы отмечают важный инсайт: на некоторых сложных акцентах и малых моделях Pseudo2Real оказывается даже эффективнее топлайна. Вектор коррекции действует как регуляризация, не давая модели переобучиться, что часто случается при прямом файнтюне на малом объёме реальных данных.
Егор Реутов