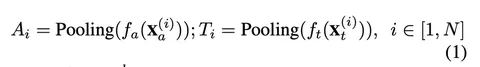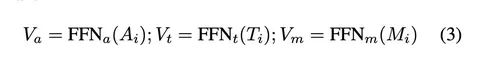В последнее время всё больше исследований посвящено голосовой активации умного ассистента без называния имени (например, «Алиса»). Это позволяет вести более естественный диалог и повышает комфорт пользователя.
Чтобы решить данную задачу, нужна ML-модель для определения, направлена речь в устройство или нет. В Яндексе такую модель называют «интонационным споттером».
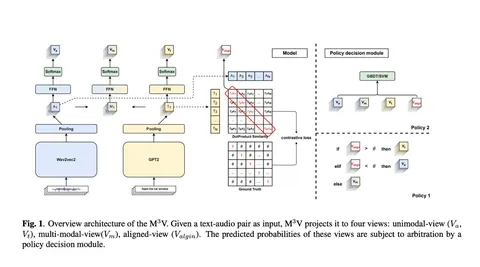
Сегодня разберём статью, в которой рассматривается случай умного помощника для автомобиля. Авторы развивают существующую схему двух энкодеров: для звука и для распознанного текста.
При распознавании речи в реальных условиях неизбежны ошибки. Необходимо сбалансировать обучение таким образом, чтобы модель видела и верно, и неверно распознанные пары «текст — речь».
Авторы предлагают использовать дополнительные модальности, а полученный фреймворк называют M³V.
Решается задача бинарной классификации «в девайс или не в девайс». В качестве энкодеров берут GPT-2 для текстовой модальности и Wav2Vec2 для звука. Результаты работы энкодера пулятся вдоль временного измерения для получения представления для всего звука (формула 1).
Результаты работы этих двух энкодеров используются в качестве входов для четырёх разных голов сети:
- чисто звуковой;
- чисто текстовой;
- мультимодальной (конкатенированной);
- выравнивания (обучаемая функция для сближения двух эмбеддингов для получения выравниваний).
Для получения сближённых эмбеддингов обучаются два проецирующих модуля: отдельно для эмбеддингов текста и отдельно — для речи (формула 3).
Проекции обучаются с помощью contrastive loss. То есть для текста и звука i-го элемента батча они учатся быть близкими (по косинусному расстоянию), а для других элементов батча — отстоять далеко.
Получается алайнмент. Contrastive score используется как компонент лосса, а косинусное произведение — как alignment score.
Итоговый лосс состоит из трёх бинарных кросс-энтропий и contrastive loss.
Коэффициенты при лоссах адаптивные. Веса энкодеров не замораживаются. Решение принимается либо по порогам трёх вероятностей и alignment score, либо с помощью SVM.
Обучение проводилось на 340 часах данных (500 тысяч записей) из машины. Тестовый набор — такой же + 560 сложных примеров с плохим распознаванием.
Эксперименты показывают, что предложенный метод позволяет добиться улучшения относительно отдельных компонент по EER даже при использовании датасета с ошибочным ASR.
Павел Мазаев