Сегодня обсудим статью о DiTAR — фреймворке авторегрессии, который объединяет языковую модель и диффузионный трансформер для синтеза речи.
Модели Text-to-Speech часто учат на дискретных токенах, но в сочетании с нюансами архитектуры, погрешностью трансформера и декодера это приводит к накоплению ошибок — а значит, затрудняет качественную генерацию непрерывных объектов.
Авторы искали новый способ предсказания непрерывных представлений аудио — и утверждают, что DiTAR значительно повышает эффективность авторегрессии для непрерывных токенов и снижает требования к вычислениям.
Совместив сильные стороны диффузионных трансформеров и больших языковых моделей, авторы:
— разбивают непрерывные представления на патчи,
— обучают каузальный авторегрессионный трансформер делать inter-patch-предсказания,
— bidirectional-диффузионный трансформер, опираясь на эти внутренние представления, делает intra-patch-предсказания.
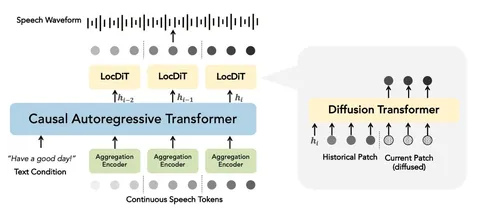
Рассмотреть архитектуру решения можно на схеме. Каузальному авторегрессионному трансформеру подают на вход набор непрерывных векторов (continuous speech tokens). А потом группируют их в патчи и ужимают в один вектор энкодером, чтобы снизить размерность и ускорить трансформер.
Диффузионный трансформер предсказывает следующий патч по выходам каузального авторегрессионного трансформера. Авторы утверждают, что если хранить историю патчей и подмешивать предыдущие на каждой новой итерации, задача станет ближе к outpainting, что помогает вырастить качество финальной генерации.
Для того чтобы сохранить возможность разнообразного семплирования, авторы добавили температуру в ODE-солвер. В DiTAR температура — момент времени в процессе генерации, когда вводится шум. Она позволяет гибко управлять вариативностью речи (от стабильной дикции до богатых интонаций) без замедления работы модели.
При генерации речи zero-shot DiTAR показывал SoTA-результаты в схожести говорящих и естественности. В следующей своей статье, DiSTAR, они опираются на наработки из этой. Но вместо непрерывных фич моделируют RVQ-токены — модель, несмотря на небольшой размер, показывает хорошие метрики.
Александр Плахин